Sistemi a catena aperta – Sistemi a catena chiusa
A volte più che mille parole, bastano un paio di immagini per dare l’idea del significato di alcuni concetti:

Come si può intuire, nel primo caso si tratta di un sistema a catena aperta, in quanto, una volta lanciato il sasso, non è poi più possibile controllarne la traiettoria, nel secondo caso invece, il monitoraggio continuo della traiettoria, con la possibilità di modificarne la curva caratteristica, mediante un controllo, viene definito come un sistema a catena chiusa.
In termini grafici di rappresentazione per “schemi a blocchi”, la differenza viene rappresentata come di seguito riportato:
Nel primo caso, un sistema a catena aperta può essere rappresentato in questo modo:

Nel secondo caso, un sistema a catena chiusa, può essere rappresentato nel seguente modo:
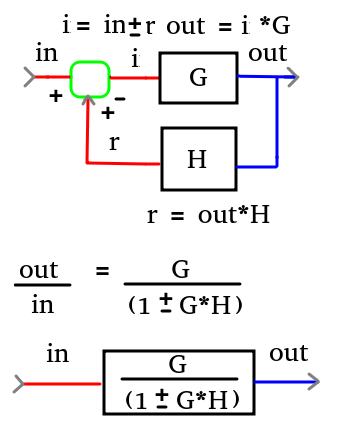
Da cui si può dedurre una notevole complessità della gestione dinamica rispetto a quello a catena aperta.
Ma, senza scendere nei particolari, non è difficile capire che un sistema a catena aperta è solo un caso particolare del sistema a catena chiusa, come facilmente esprimibile dalla seguente illustrazione.
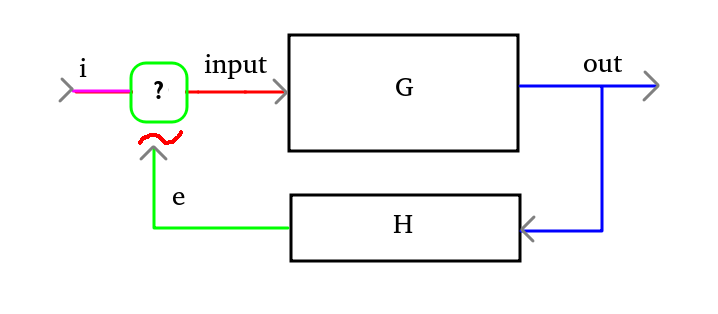
Questo mi sembrava il modo giusto per introdurre l’argomento di cui voglio trattare in questo articolo.
Sequenze – Vettori – Simulazioni – Soluzioni
Lo spunto parte dalla ricerca sviluppata da Alessandro Delfanti, professore associato della Facoltà di Informatica dell’Università di Toronto che tratta un argomento inerente il connubio, in alcuni ambienti di lavoro tra uomo e macchina.
Delfanti ha svolto una ricerca (nel 2017) basata su numerose interviste a lavoratori, del primo magazzino Amazon italiano.
L’analisi del professore, era inerente alcuni tipi di mansioni che sono parte organica del contesto logistico della gestione del magazzino.
Per questo articolo, prendiamo in considerazione il lavoro dello “Stower”: bisogna considerare che la merce che ordiniamo online su Amazon viene stoccata in modo caotico.
Il processo che seguono i lavoratori del magazzino è composto da quattro passaggi che iniziano con la ricezione della merce (receive), passano allo stoccaggio (stow), vengono prelevati (pick), e infine impacchettati per la spedizione (pack).
Questo lo so, anche perché ho superato le procedure inerenti i criteri di assunzione per lavorare nei magazzini Amazon.
Il lavoratore che si trova al secondo step del processo lavorativo, il cosiddetto “Stower”, ha il compito di prendere la merce, da un contenitore “Tote” e inserirla all’interno di una cella “Bin” della torre, armadio “Pod” nella zona assegnatagli.
All’interno del Tote la merce è posta alla rinfusa, ha vari pesi e varie dimensioni (una disposizione confusa organizzata”, come dicono “loro”.
I Bin sono dei contenitori disposti nel Pod, ed hanno sei dimensioni diverse, in relazione agli ingombri degli oggetti da stoccare.
Un dispositivo ottico, indica allo Stower, dove essere posizionato l’articolo prelevato dal Tote.
Lo stower ha discrezionalità nel prelievo della merce e lo fa in relazione alla disponibilità di inserimento dell’oggetto in uno dei Bin liberi.
All’atto del “login”, ad inizio turno, il sistema propone una serie di “question test” all’operatore, inerenti lo stato psicofisico.
Ovviamente, le “sequenze operative” vengono monitorate in modo costante, poiché è il sistema informatico il “core” del magazzino.
Il lettore di codici a barre, oltre a fornire indicazioni pratiche per il posizionamento della merce, e dunque “svolgere attività di management,” ovviamente l’algoritmo di monitoraggio, inoltra un feedback sulle prestazioni del lavoratore.
Lo strumento è, secondo i lavoratori, non troppo preciso nell’indicare il posizionamento ottimale degli oggetti e “capita che la merce non sia nel punto più vicino poi al picker, costringendo di fatto il lavoratore a mantenere un ritmo molto elevato e spostarsi continuamente,” Questo, ed altre interessanti considerazioni spiegava Delfanti nella sua ricerca.
Quando il lavoratore termina il suo turno, il sistema congeda l’operatore con delle frasi di cortesia, ma, per quanto ne so io, non chiede al lavoratore se il suo livello di “stress” ha subito una variazione inerente il lavoro svolto.

Da quanto sopra, mi è scaturita l’idea per scrivere questo articolo che vuole essere un esempio didattico per l’utilizzo di Python e delle librerie ausiliarie inerenti il deep learning ed il machine learning:
TensorFlow: è considerata una delle migliori librerie Python per applicazioni di deep learning, sviluppata dal Google Brain Team, offre un’ampia gamma di strumenti flessibili, strumenti e risorse della community Open Source.
Keras: la libreria Python strettamente correlata a Tensorflow, e utilizzata per attività di deep learning, consente test rapidi della rete neurale profonda. Keras fornisce gli strumenti necessari per costruire modelli, visualizzare grafici e analizzare set di dati.
Scikit-learn: è una libreria di apprendimento automaticoche contiene algoritmi di classificazione, regressione e clustering (raggruppamento) e macchine a vettori di supporto, regressione logistica, classificatore bayesiano,
NumPy: è la libreria utilizzata per l’elaborazione di matrici e array multidimensionali di grandi dimensioni. Si basa su un ampio set di funzioni matematiche di alto livello, che la rende particolarmente utile per calcoli scientifici fondamentali nelle tecniche di deep learning.
Pandas: una delle librerie Python open source utilizzate principalmente nella scienza del trattamento dei dati e in ambito di deep learning, questa libreria fornisce strumenti per la manipolazione e l’analisi dei dati.
Matplotlib: una libreria di per la creazione di grafici che viene utilizzata per creare una vasta gamma di visualizzazioni statiche o animate e interattive, come grafici di linea, grafici a dispersione, grafici a barre, istogrammi ecc.
Csv: una libreria python per il trattamento di file del tipo “Comma Separated Values”. Si tratta di una delle estensioni più utilizzate soprattutto in ambito scientifico o quando si ha comunque a che fare con grosse quantità di dati. Una modalità di archiviazione per dati strutturati in tabulati stile foglio di calcolo.
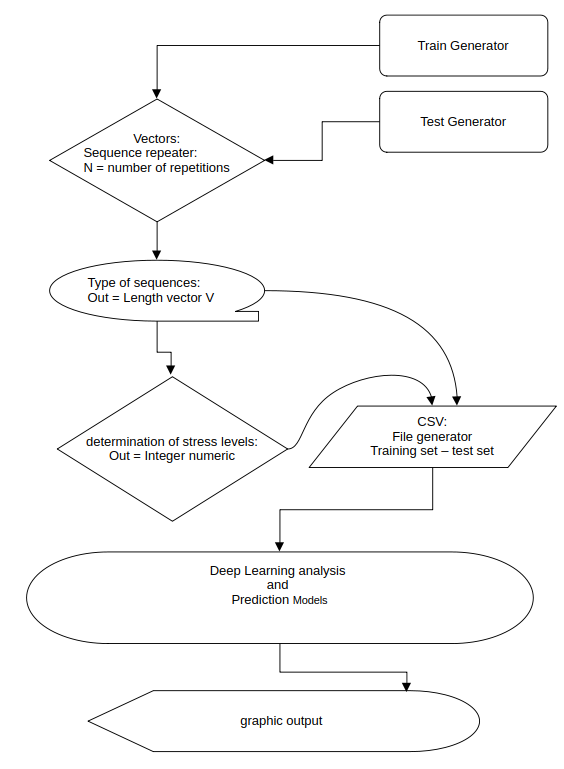
Grosso modo, la struttura di questo progetto didattico è stata concepita in questo modo:
Struttura del progetto didattico
Pezzi di codice
Il linguaggio Python è un linguaggio abbastanza leggibile, ma in questo caso, data la complessità del progetto, verranno riportate solo le parti più significative delle varie subrutines (funzioni) che sono state adottate per la realizzazione sperimentale di tre applicazioni tipiche utilizzanti sistemi di deep learnig di previsione.
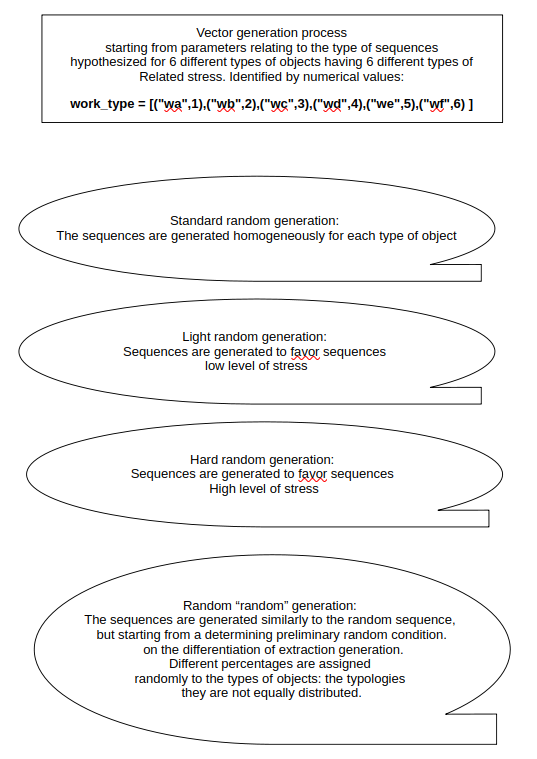
Generatori di sequenze
In sostanza si tratta di quattro funzioni che generano, partendo dalle specifiche introdotte dalla libreria “Random” di Python, delle sequenze basate sulla lista:
work_type = [("wa",1),("wb",2),("wc",3),("wd",4),("we",5),("wf",6) ]
è una lista di tuple che contengono una stringa identificativa della tipologia di oggetti e un valore numerico che potrebbe indicare un livello di “complessità inerente la funzione di stoccaggio”, in questo caso puramente didattico.
Per la generazione delle sequenze, basta solo importare la librerie di python Random:
import random
Per fare un test di funzionamento, bastano poche righe di codice:
work_type = [("wa",1),("wb",2),("wc",3),("wd",4),("we",5),("wf",6) ]
l=len(work_type)
print("lunghezza del vettore", l)
wr = random.randint(0, (l-1))
print("wr", wr, "work_type", work_type[wr])
print ("work_type", work_type[wr][1])
wtr=work_type[wr]
print ("wtr", wtr)
Un possibile output:
lunghezza del vettore 6
wr 2 work_type ('wc', 3)
work_type 3
wtr ('wc', 3)
La routine di generazione di sequenze standardizzate potrebbe essere generata da un codice simile a quello di seguito riportato, dove viene definita una variabile indicante il numero di sequenze da generare.
Codice per Sequenza standard:
def standard_s():
number_s = 360 # 360
nw= 0
T=0
nwa=0
nwb=0
nwc=0
nwd=0
nwe=0
nwf=0
yO=[]
x=[]
while nw < number_s:
nw=nw+1
print("number sequence",nw)
wr = random.randint(0, (l-1))
wtr=work_type[wr]
print ("wtr=",wtr)
T=work_type[wr][1] # value
O=work_type[wr][0] # index
print("O=", O, "T=", T )
x.append(nw)
yO.append(T)
if O == "wa":
nwa=nwa+1
if O == "wb":
nwb=nwb+1
if O == "wc":
nwc=nwc+1
if O == "wd":
nwd=nwd+1
if O == "we":
nwe=nwe+1
if O == "wf":
nwf=nwf+1
print("sequence_type", "wa=",nwa, "wb=", nwb, "wc=", nwc, "wd=",nwd, "we=",nwe, "wf=", nwf)
# Creazione del grafico
plt.bar(x, yO)
plt.title("Grafico a barre sequence standard")
plt.xlabel("Nuber sequences")
plt.ylabel("operation type")
plt.show()
return x, yO
output a terminale:
…
number sequence 359
wtr ('wb', 2)
O wb T= 2
number sequence 360
wtr ('wd', 4)
O wd T= 4
sequence_type wa= 61 wb= 58 wc= 59 wd= 68 we= 57 wf 57
Output grafico:
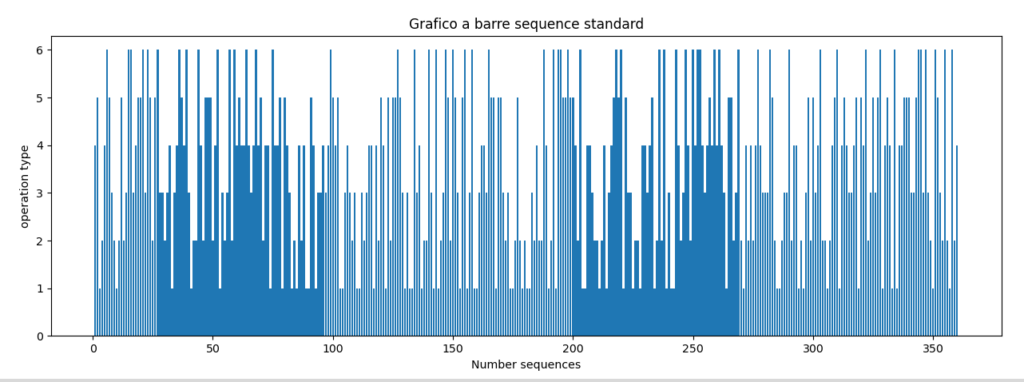
Come si può notare, il numero totale, per ogni tipologia di materiale vene pressoché equamente distribuito: sequence_type wa= 61 wb= 58 wc= 59 wd= 68 we= 57 wf 57.
La scelta di una lunghezza di 360 elementi è stata fatta anche per una visualizzazione di questo tipo, che potrebbe essere immaginata come un quadrante di un orologio a lancette: (Grafico polare ruotato nel verso dell’orologio):
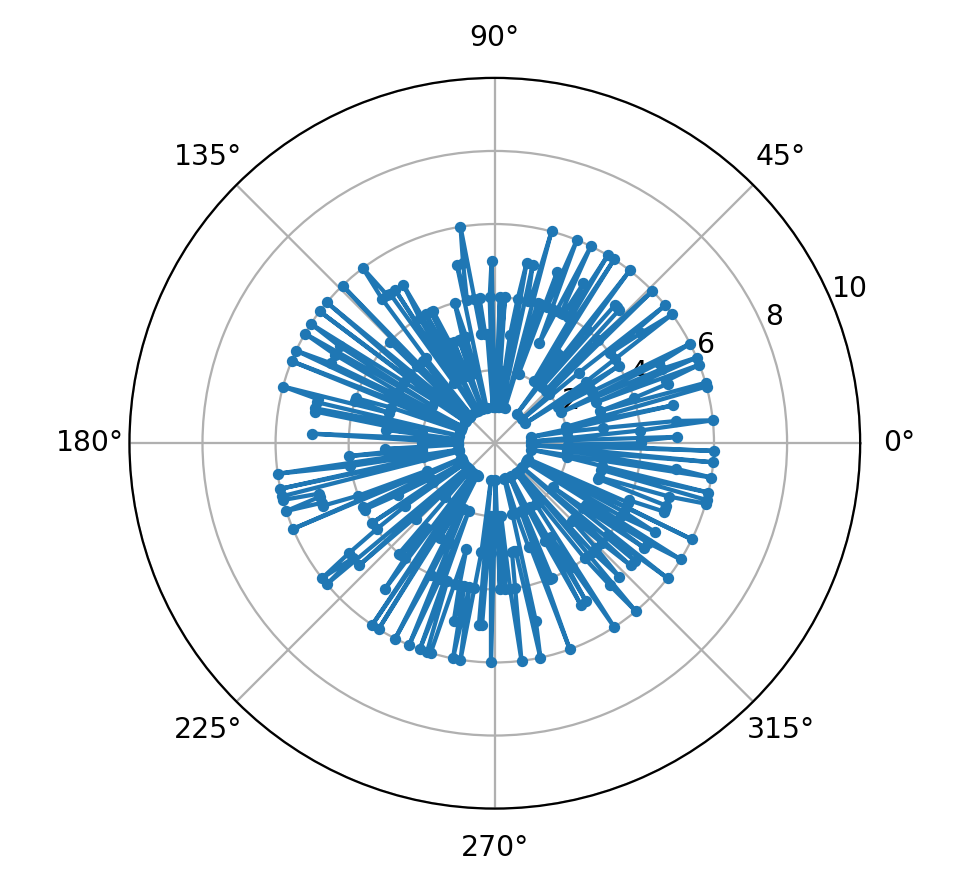
L’output grafico ci viene fornito dalla libreria Matplotlib, richiamata previamente dalla istruzione:
import matplotlib.pyplot as plt
Per la generazione di sequenze caratterizzate da un “condizionamento”, in fase di generazione, come potrebbe essere ad esempio necessario per ottenere una sequenza con preponderanza degli oggetti caratterizzati dai “valori” minori, serve adottare qualche accortezza, in modo tale da favorire l’estrazione randomica per quella tipologia di oggetti, ad esempio, mediante l’utilizzo di alcuni parametri, come di seguito riportato:
Codice per Sequenza light:
def light_s():
number_s = 360
nw= 0
T=0
Total=0
nwa=0
nwb=0
nwc=0
nwd=0
nwe=0
nwf=0
a=True
b=True
c=True
d=True
e=True
f=True
maxwa = 120 #48
maxwb = 80 #35
maxwc = 75 #26
maxwd = 50 #14
maxwe = 25 #7
maxwf = 15 #5
iup=0
sum_max = maxwa + maxwb + maxwc + maxwd + maxwe + maxwf
while nw < number_s: nw=nw+1 print("number of work",nw) wr = random.randint(0, (l-1)) T=work_type[wr][1] O=work_type[wr][0] print("O=", O, "T=", T ) if O == "wa": maxwa = maxwa-1 if maxwa > 0:
nwa=nwa+1
x.append(nw)
yO.append(T)
if maxwa <= 0: nw=nw-1 a = False print ("a=", a) if O == "wb": if maxwb > 0:
nwb=nwb+1
maxwb = maxwb-1
x.append(nw)
yO.append(T)
if maxwb <= 0: nw=nw-1 b = False print ("b=", b) if O == "wc": if maxwc > 0:
nwc=nwc+1
maxwc = maxwc-1
x.append(nw)
yO.append(T)
if maxwc <= 0: nw=nw-1 c = False print ("c=", c) if O == "wd": if maxwd > 0:
nwd=nwd+1
maxwd = maxwd-1
x.append(nw)
yO.append(T)
if maxwd <= 0: nw=nw-1 d = False print ("d=", d) if O == "we": if maxwe > 0:
nwe=nwe+1
maxwe = maxwe-1
x.append(nw)
yO.append(T)
if maxwe <= 0: nw=nw-1 e = False print ("e=", e) if O == "wf": if maxwf > 0:
nwf=nwf+1
maxwf = maxwf-1
x.append(nw)
yO.append(T)
Total=Total+T
if maxwf <= 0:
nw=nw-1
f = False
print ("f=", f)
if (a==False and b==False and c==False and d==False and e==False and f==False) and nw < number_s:
print("maxwa", maxwa)
print("maxwb", maxwb)
print("maxwc", maxwc)
print("maxwd", maxwd)
print("maxwe", maxwe)
print("maxwf", maxwf)
maxwa += 1
maxwb += 1
maxwc += 1
iup +=1
print ("increments update",)
nw= nwa+nwb+nwc+nwd+nwe+nwf
print ("increment update counter", iup)
print ("nw=", nw)
print ("sum max", sum_max, nw)
print("operations", "wa=",nwa, "wb=", nwb, "wc=", nwc, "wd=",nwd, "we=",nwe, "wf", nwf)
# Creazione del grafico
plt.bar(x, yO)
plt.title("Grafico a barre sequence light")
plt.xlabel("Nuber sequences")
plt.ylabel("operation type")
plt.show()
return x, yO
output a terminale:
number of work 360
O= wc T= 3
c= False
increments update
increment update counter 2
nw= 366
sum max 365 366
operations wa= 119 wb= 81 wc= 76 wd= 50 we= 25 wf 15
Output grafico a barre:
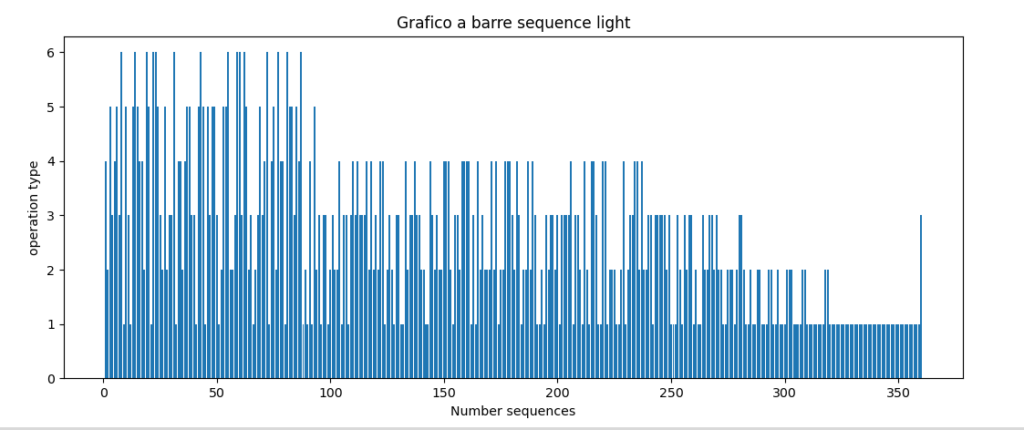
Grafico polare (ruotato nel verso dell’orologio):
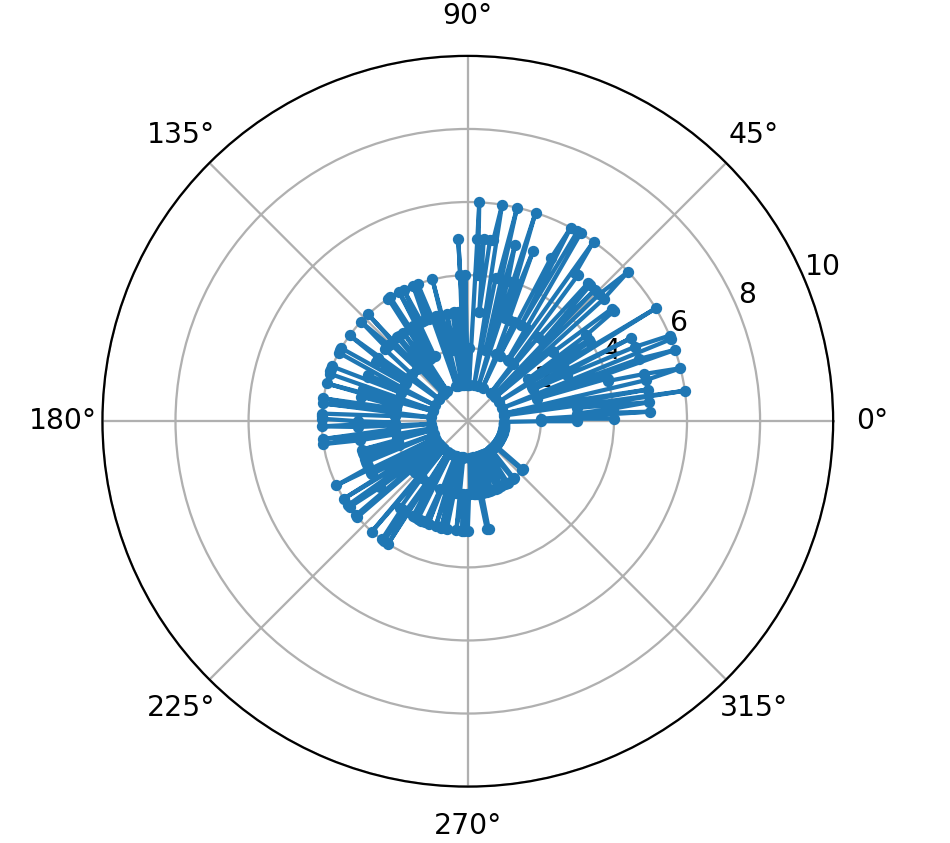
Come si può verificare dalla lettura del codice, ad un certo punto vengono favorite solo le estrazioni per gli oggetti a minor valore.
Con accorgimenti del tutto simili, si può generare una sequenza che propenda per favorire invece gli oggetti a maggior valore, come indicato dalla sintesi del codice di seguito riportato.
Sintesi del codice per sequenza hard:
def hard_s():
number_s = 360
nw= 0
T=0
Total=0
nwa=0
nwb=0
nwc=0
nwd=0
nwe=0
nwf=0
colors=[]
sizes=[]
a_s=True
b_s=True
c_s=True
d_s=True
e_s=True
f_s=True
maxwa = 20
maxwb =30
maxwc = 40
maxwd = 60
maxwe = 80
maxwf = 100
iup=0
sum_max = maxwa + maxwb + maxwc + maxwd + maxwe + maxwf
while len(yh) < number_s: nw=nw+1 wr = random.randint(0, (l-1)) T=work_type[wr][1] O=work_type[wr][0] if O == "wa": maxwa = maxwa-1 if maxwa > 0:
nwa=nwa+1
xh.append(nw)
yh.append(T)
if maxwa <= 0: nw=nw-1 a_s = False …. if O == "wf": if maxwf > 0:
nwf=nwf+1
maxwf = maxwf-1
xh.append(nw)
yh.append(T)
if maxwf <= 0:
nw=nw-1
f_s = False
if (a_s==False and b_s==False and c_s==False and d_s==False and e_s==False and f_s==False) and nw < number_s:
maxwd += 1
maxwe += 1
maxwf += 1
iup +=1
nw= nwa+nwb+nwc+nwd+nwe+nwf
print ("increment update counter", iup)
print ("nw=", nw)
# Creazione del grafico
plt.bar(xh, yh)
plt.title("Grafico a barre sequence hard")
plt.xlabel("Number sequences")
plt.ylabel("operation type")
plt.show()
plt.close()
print ("lenyO", len(yh))
print ("END HARD SEQUENCE")
x= xh
yO = yh
polar_plotting(x,yO)
return x, yO
output grafico
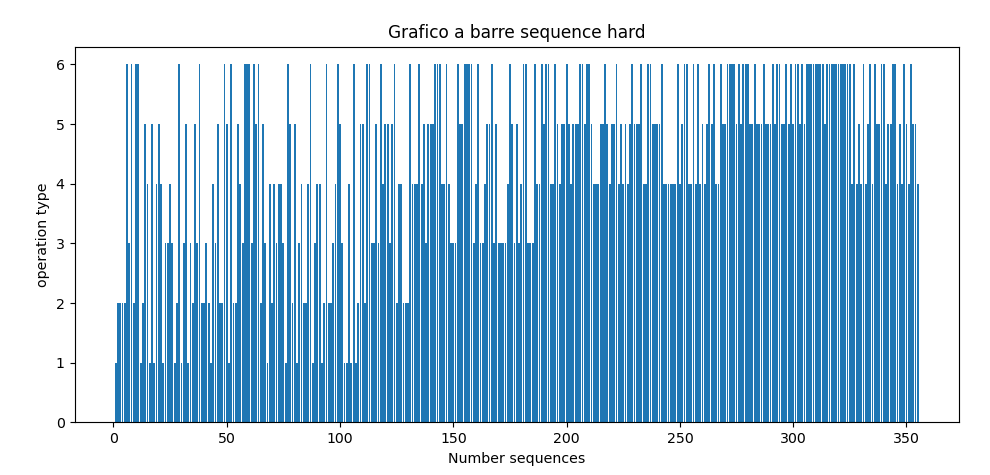
Grafico polare (ruotato nel verso dell’orologio):
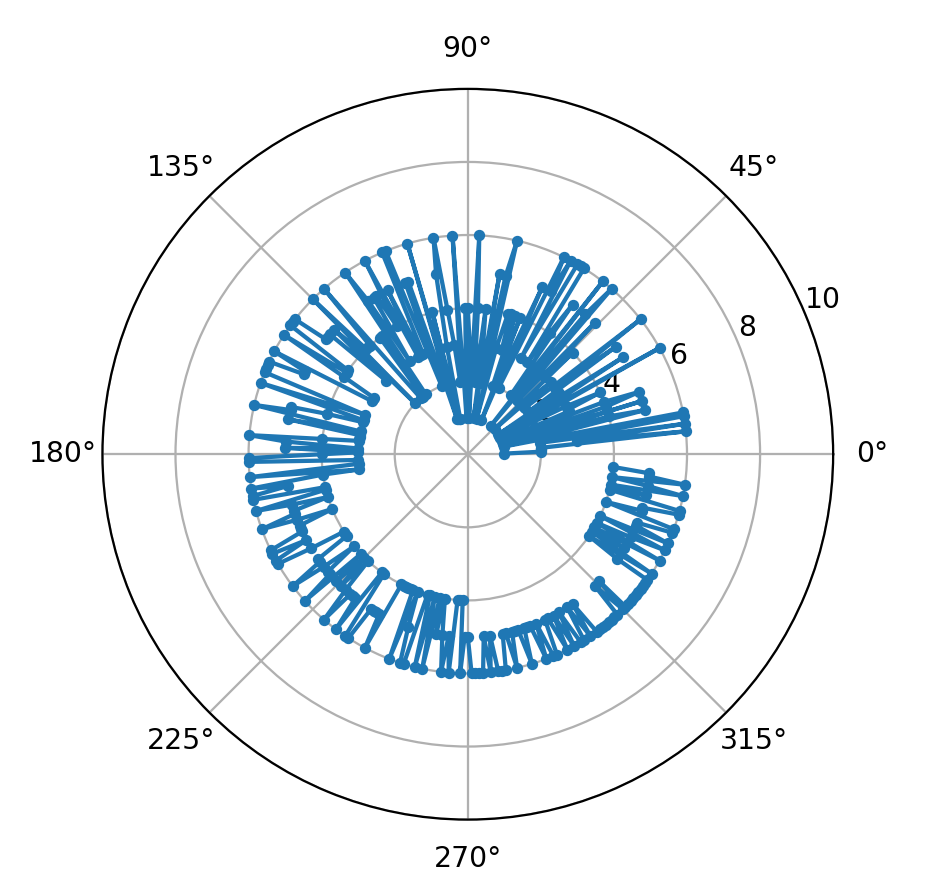
Come si può facilmente notare, in questo caso vengono favorite le sequenze di “oggetti” a maggior “valore”. Il termine valore, potrebbe essere associato ad esempio ad un livello di stress attribuibile alla operazione di stoccaggio, vuoi perché l’oggetto è pesante oppure perché lo si deve stoccare in una posizione scomoda, magari in alto nel “Pod”, usando una scaletta.
Infine, ho introdotto una variante per generare un tipo di sequenza casuale, ma partendo dalla tipologia degli oggetti, in tal modo si può sbilanciare o meno una serie tipologica e di conseguenza l’intera generazione di sequenze.
Codice della sequenza “Casual”:
def casual_s():
number_s = 360
nw= 0
T=0
Total=0
nwa=0
nwb=0
nwc=0
nwd=0
nwe=0
nwf=0
colors=[]
sizes=[]
a_s=True
b_s=True
c_s=True
d_s=True
e_s=True
f_s=True
max =[]
for m in range(6):
r = random.randint(10, 100)
max.append(r)
maxwa = max[0]
maxwb = max[1]
maxwc = max[2]
maxwd = max[3]
maxwe = max[4]
maxwf = max[5]
iup=0
sum_max = maxwa + maxwb + maxwc + maxwd + maxwe + maxwf
print ("sum max", sum_max)
while len(yc) < number_s: nw=nw+1 wr = random.randint(0, (l-1)) T=work_type[wr][1] O=work_type[wr][0] if O == "wa": maxwa = maxwa-1 if maxwa > 0:
nwa=nwa+1
xc.append(nw)
yc.append(T)
if maxwa <= 0: nw=nw-1 a_s = False …. if O == "wf": if maxwf > 0:
nwf=nwf+1
maxwf = maxwf-1
xc.append(nw)
yc.append(T)
if maxwf <= 0:
nw=nw-1
f_s = False
if (a_s==False and b_s==False and c_s==False and d_s==False and e_s==False and f_s==False) and nw < number_s:
maxwa += 1
maxwb += 1
maxwc += 1
maxwd += 1
maxwe += 1
maxwf += 1
iup +=1
print ("increments update", iup)
nw= nwa+nwb+nwc+nwd+nwe+nwf
print ("increment update counter", iup)
print("operations CASUAL SEQUENCE", "wa=",nwa, "wb=", nwb, "wc=", nwc, "wd=",nwd, "we=",nwe, "wf", nwf)
# Creazione del grafico
plt.bar(xc, yc)
plt.title("Grafico a barre sequence casual")
plt.xlabel("Number sequences")
plt.ylabel("operation type")
plt.show()
plt.close()
print("len yc",len(yc))
print ("END CASUAL SEQUENCE")
polar_plotting(xc, yc)
return xc, yc
Output a terminale:
wr 0 work_type ('wa', 1)
1
sum max 259
increments update 111
increment update counter 111
operations CASUAL SEQUENCE wa= 50 wb= 39 wc= 47 wd= 103 we= 49 wf 72
output grafico
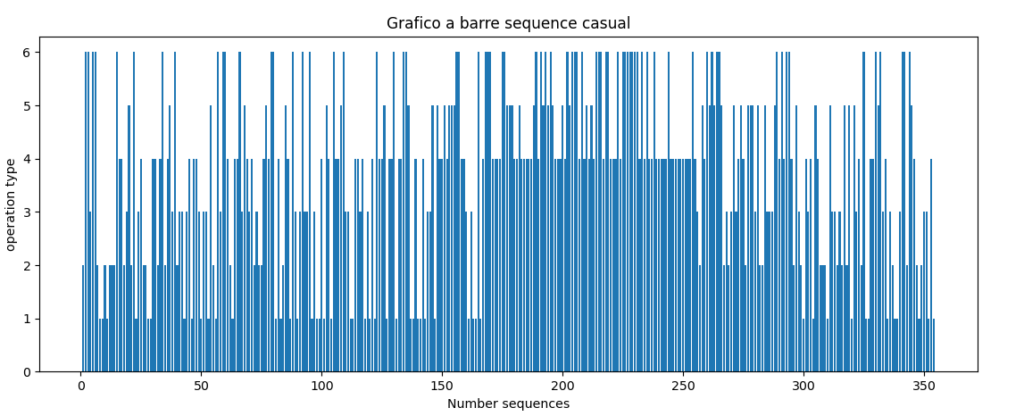
Grafico polare (ruotato nel verso dell’orologio):
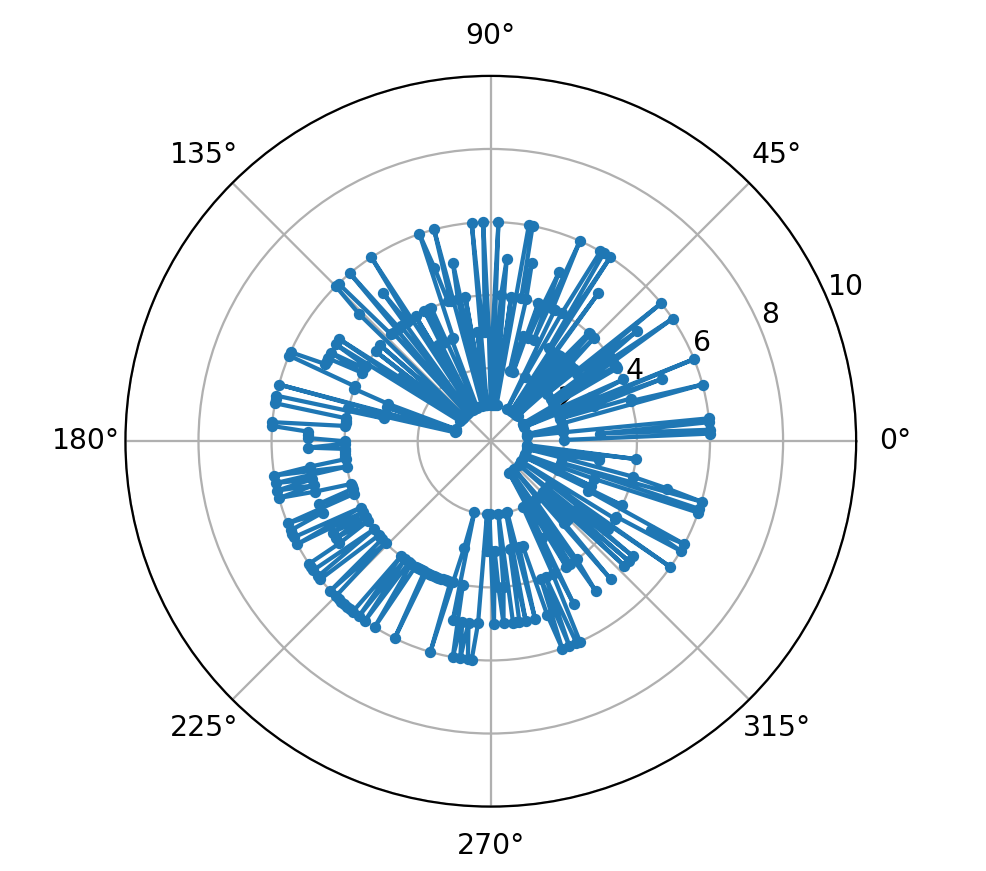
Come si può notare in questo caso viene presentata una anomalia sequenziale nel quadrante 180°-270° riportata anche a terminale:
operations CASUAL SEQUENCE wa= 50 wb= 39 wc= 47 wd= 103 we= 49 wf 72
Ora, supponiamo di analizzare le sequenze avendo un criterio per determinarne il livello di stress in base ad esempio al fatto che si presentino consecutivamente degli oggetti a valore alto da stoccare, come indicato dalle seguenti linee di codice:
Sintesi di codice per la fase di analisi:
…
event = False
for i in range(1,len(yO),1):
if i < (len(yO)-step): s= yO[i:i+step] if event == True: j +=1 if j >= 2:
j=0
event = False
stress = stress -1
if type[key] == 6 or type[key] == 5:
stress = stress +1
for key in range (len(type)):
seq = s.count(type[key])
if seq >= (step-1):
stress +=1
event = True
breakprint ("lo stress dell'ultima sequenza è ", stress)
return stress
Se esaminando (scansionando) una sequenza, si denota che vi siano successioni di oggetti appartenenti ai due livelli alti di difficoltà per l’immagazzinaggio, in un determinato range di controllo, allora si incrementa un contatore del livello di stress, cosicché si potrebbero registrare ad esempio situazioni di questo genere per le sequenze hard:
output a terminale:
sequence_type wa= 63 wb= 50 wc= 54 wd= 66 we= 60 wf= 67
START ANALYSIS
increment update counter 63
nw= 360
lenyO 360
END HARD SEQUENCE
lo stress dell'ultima sequenza è 115
mentre per una sequenza casual, ad esempio si potrebbe verificare una situazione come quella di seguito riportata:
output a terminale:
sequence_type wa= 58 wb= 59 wc= 49 wd= 65 we= 66 wf= 63
START ANALYSIS
sum max 469
increments update 0
nw= 360
len yO 360
END CASUAL SEQUENCE
lo stress dell'ultima sequenza è 38
Come si può notare, a prima vista, le sequenze si assomigliano, in termini numerici, ma sono totalmente diverse in termini di valori di stress:
Hard Sequence: sequence_type wa= 63 wb= 50 wc= 54 wd= 66 we= 60 wf= 67 – stress=115
Casual Sequence: sequence_type wa= 58 wb= 59 wc= 49 wd= 65 we= 66 wf= 63 – stress= 38
A questo punto, potrebbe essere interessante cercare di vedere come si può comportare uno o più sistemi di analisi basati su tecniche di deep learning, e per fare questo bisogna generare delle sequenze per “trainare” il modello e altre sequenze per “testare” il modello che si vuole utilizzare.
L’obbiettivo quindi è quello di costruire un dataset contenente una quantità di vettori, associandoli ai relativi livelli di stress, sia per il training che per il test, questo lo si può fare scrivendo dei file del tipo “Train_set.csv” e “Test_set.csv”.
Codice per generazione del “Train_set.csv” e del “Test_set.csv”:
def train_gen():
print("START TRAIN GENERATOR")
global yO, stress, v_a, mv
for d in range (dimension_train):
vectors()
analysis()
dv.append(yO)
ds.append(stress)
yO=[]
rwd=[]
rt=[]
for rw in range (dimension_train):
rwd=dv[rw]
rwd.append(ds[rw])
print ("rwd: ",rwd)
rt.append(rwd)
with open('Train_seq_num.csv', 'w', newline='') as csvfile:
rw_writer = csv.writer(csvfile)
for rw in range (dimension_train):
rw_writer.writerow(rt[rw])
v=[]…for c in range(len(dv)):
v.append(len(dv[c]))
mv= max(v)
for p in range (len(dv)):
x=max(v)-v[p]
vx=dv[p]
for n in range (x):
vx.append(0)
v_a.append(vx)
…
return v_a, ds, mv
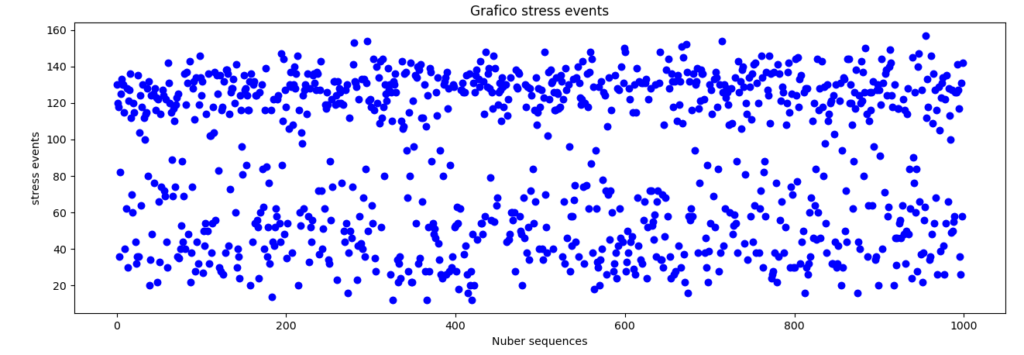
Questa funzione genera un file il cui titolo è “Train_seq_num.csv”, contenente mille vettori:
dimension_train= 1000
di lunghezza 360 valori inerenti il livello di difficoltà inerente la tipologia del materiale, più il valore di stress associato: rwd.append(ds[rw]) posizionato nell’ultima casella del vettore.
I vettori sono generati in relazione a delle sequenze casuali determinate dalla funzione “vectors()”:
def vectors():
global yO
# vectors generator
vg = 1
for counter in range (vg):
v = random.randint(1, 2)
if v == 1:
hard_s()
if v == 2:
casual_s()
print ("vector N.", counter)
In termini grafici quindi la questione si potrebbe riassumere in questo modo:
Lo stesso dicasi per la generazione del file di test “Test_seq_num.csv”, che in termini grafici potrebbe risultare qualcosa del genere:
A questo punto sono disponibili i dati su cui poter provare alcuni modelli di deep leanrning per vedere quali siano i risultati di previsione ottenibili.
Per fare questo c’è l’esigenza di accedere ai due files per estrarne i dati di treinig e di test.
A questo compito viene delegata la libreria Pandas di Python e lo assolve tramite le sequenti linee di codice:
Estrazione dati con Pandas (e elaborazione con Numpy)
import pandas as pd
import numpy as np
…
train_set = pd.read_csv("Train_seq_num.csv", header = None)
print("train_set ",train_set.head(3))
print("len columns ",len(train_set.columns))
print("last columns", train_set[360]) # stress vector
trv_s = np.array(train_set[360])
vtr_g=np.array(train_set)
print("len vtrg",len(vtr_g))
vtr= vtr_g[0]
vtr = vtr[:-1]
print("len_vtr=",len(vtr))
print("len_stress_vector=",len(trv_s))
vtr= vtr_g[len(trv_s)-1]
vtr = vtr[:-1]
tr_v=[]
for tr in range (len(trv_s)):
vtr= vtr_g[tr]
vtr = vtr[:-1]
tr_v.append(vtr)
print("len_tr_v", len(tr_v))
#-----------------X_train = tr_v
y_train = trv_s
#-----------------#datset test extaction
test_set = pd.read_csv("Test_seq_num.csv", header = None)
print("test_set ",test_set.head())
print("len columns ",len(test_set.columns))
print("last columns", test_set[360]) # stress vector
tev_s = np.array(test_set[360])
vte_g=np.array(test_set)
print("len vte_g",len(vte_g))
vte= vte_g[0]
vte = vte[:-1]
print("len_vte=",len(vte))
print("len_stress_v_test=",len(tev_s))
vte= vte_g[len(tev_s)-1]
vte = vte[:-1]
te_v=[]
for te in range (len(tev_s)):
vte= vte_g[te]
vte= vte[:-1]
te_v.append(vte)
print("len_te_v", len(te_v))
#-----------------X_test = te_v
y_test = tev_s
#-----------------
In particolare, vi è da notare quanto segue: i file contengono delle righe aventi la lunghezza dei record memorizzati: 360+1 (partendo da “0”),
lo si può notare con la richiesta di stampa del “head”: print("train_set ",train_set.head(3))
train_set 0 1 2 3 4 5 6 7 8 … 352 353 354 355 356 357 358 359 360
0 3 1 2 5 3 3 1 3 3 … 5 4 6 6 6 5 5 6 130
1 5 3 1 5 2 3 2 5 5 … 4 6 6 6 6 4 4 6 120
2 5 5 4 6 1 3 1 4 1 … 4 4 6 6 5 5 6 5 118
3 6 6 1 1 6 6 4 5 5 … 2 6 2 2 4 1 5 5 36
4 2 3 2 4 4 3 3 5 6 … 5 4 6 4 2 6 2 5 82
[5 rows x 361 columns]
In particolare, l’ultima colonna contiene il valore di “stress”, associato al vettore:
print("last columns", train_set[360])
last columns 0 130
1 120
2 118
3 36
4 82
…
995 36
996 26
997 131
998 58
999 142
Name: 360, Length: 1000, dtype: int64
E’ fondamentale però, dover suddividere i dati di ingresso (i vettori contenenti le sequenze con i valori di livello di difficoltà degli oggetti, dai dati di “stress” arbitrariamente calcolati con il criterio visto precedentemente, in modo da ottenere due liste:
X_train (vettori di ingresso per i modelli di training)
y_train (livelli di “stress”, associato ad ogni sequenza vettoriale per il training del modello.
Analogamente, per il test inerente il modello, si dovranno estrarre i vettori:
X_test (vettori di ingresso per i modelli di test)
y_test (livelli di “stress”, associato ad ogni sequenza vettoriale per il test del modello.
La libreria Numpy viene utilizzata proprio a questo scopo.
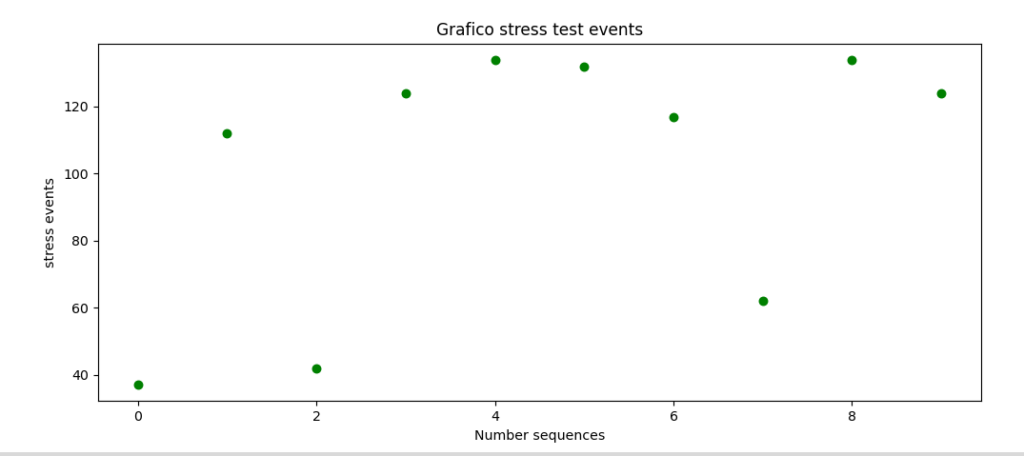
Pertanto, ad esempio, in questo caso, il vettore y_test avrà la seguente caratteristica:
y_test = tev_s
print ("te_s", tev_s)
te_s [ 37 112 42 124 134 132 117 62 134 124]
Quello che c’è da aspettarsi dalle previsioni dei modelli di deep learning è qualcosa che si avvicini il più possibile proprio a questi valori!
Sequential + LSTM Model
Come accennato inizialmente, vi possono essere svariati modelli che potrebbero essere testati per verificarne la loro efficienza in questo frangente, che potrebbe per alcuni sembrare semplice, ma non è comunque scontato.
Una delle librerie più utilizzate in questo ambito è appunto “Tensorflow”, la cui peculiarità è quella di lavorare bene con le CPU, ma di avere delle performance eccellenti con le GPU! (unità di elaborazione grafica ad alte prestazioni), ma ovviamente, il suo ambiente ideale sono le TPU: unità di elaborazione tensoriale.
TensorFlow è di gran lunga il motore di AI più utilizzato, anche perché è Open Source ed è supportato in tutto il mondo da una vasta community.
TensorFlow combina vari modelli e algoritmi di machine learning e deep learning (o networking neurale) e li rende accessibili tramite un’interfaccia comune.
Anche Keras è una libreria open-source di reti neurali di alto livello, progettata per essere semplice da usare, modulare e facilmente estendibile ed in particolare, questa libreria è scritta in Python ed il supo principale “supporter” è proprio Tensorflow.
Con Tensorflow e Keras si possono quindi configurare delle reti neurali, ed è proprio con questi strumenti che cercherò di fornire dei modelli, a scopo didattico, per cercare di generare delle previsioni.
Uno di questi modelli, potrebbe essere quello che fa riferimento a LSTM (long-short term memory), che possiede un struttura interna in grado di propagare le informazioni attraverso lunghe sequenze.
Ci tengo però a precisare, sin da subito, che i modelli possono essere costruiti con vari sistemi, quelli proposti sono solo alcuni, che, oltre a far riferimento ad uno strato della rete, appositamente modellato per l’utilizzo di LSTM, fa riferimento anche ad altri strati che concorrono alla determinazione del comportamento della Deep Learning Network.
In particolare, nel modello proposto, si utilizzerà un primo strato di input che fa riferimento alla funzione “Sequential”, mentre il penultimo strato fa riferimento ad una funzione di attivazione denominata “relu”, che in termini grafici si presenta in questo modo:
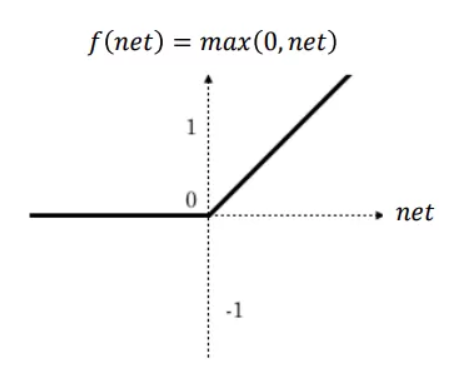
L’ultimo strato, infine, avrà un solo neurone che produrrà un valore, quello di previsione, inerente l’elaborazione ripetuta dei valori in ingresso per un numero di volte che si possono stabilire a priori o possono essere determinate in relazione a dei parametri inerenti una stima di prestazione.
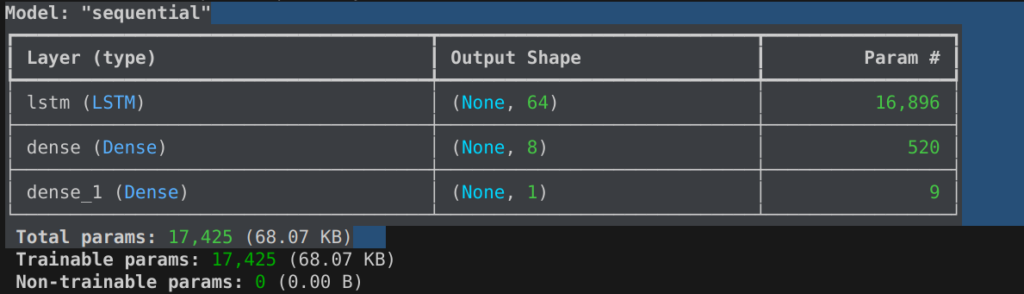
In parole semplici, il primo modello sperimentabile per effettuare una previsione di stress, date una serie di sequenze di trainig sui dati, è il seguente:
sintesi di codice per LSTM:
model = Sequential()
model.add(tf.keras.Input(shape=(360, 1)))
model.add(LSTM(64))
model.add(Dense(8, activation="relu"))
model.add(Dense(1))
Una volta scelto il modello, bisogna “passare a questo, i parametri di lavoro, che ne determinano il comportamento:
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['mae'])
In questo caso, il modello utilizzerà il parametro “loss”, che è una funzione che serve per determinare l’errore tra il valore che il modello produce, mano a mano che le sequenze di training (epoche), vengono implementate e il valore “target”, contenuto nel vettore y_train, per ogni vettore di ingresso, in questo caso la formula è la seguente:loss = mean(square(y_true – y_pred))
La mertica di controllo adottata per visualizzare l’errore in questo caso è stata adottata in relazione alla seguente formula:keras.metrics.MeanAbsoluteError(name="mean_absolute_error", dtype=None)
che fa riferimento alla seguente formula: metrics = mean(abs(y_true - y_pred))
Quindi il modello viene “lanciato” per eseguire il trainig sui dati, memorizzandone i parametri su una variabile:
history=model.fit(X_train, y_train, epochs=100, batch_size=36)
dove il valore “batch_size”, definisce il numero di campioni che verranno propagati attraverso la rete.
quindi, in questo caso avendo 360 campioni di addestramento ed un batch_size pari a 36. L’algoritmo preleva i primi 36 campioni (dal 1 ° al 36 °) dal set di dati di addestramento e modella la rete, dunque, in questo caso, setaccia per 100 volte tutti i dati in ingresso contenuti in X_train, a blocchi di 36.
I risultati si possono riportare in termini grafici mediante le seguenti linee di codice:
plt.figure(figsize=(10, 6))
plt.plot(history.history['mae'], label='mae')
plt.plot(history.history['loss'], label='loss')
plt.legend()
plt.show()
che equivale ad ottenere ad esempio, qualcosa di simile a questo:
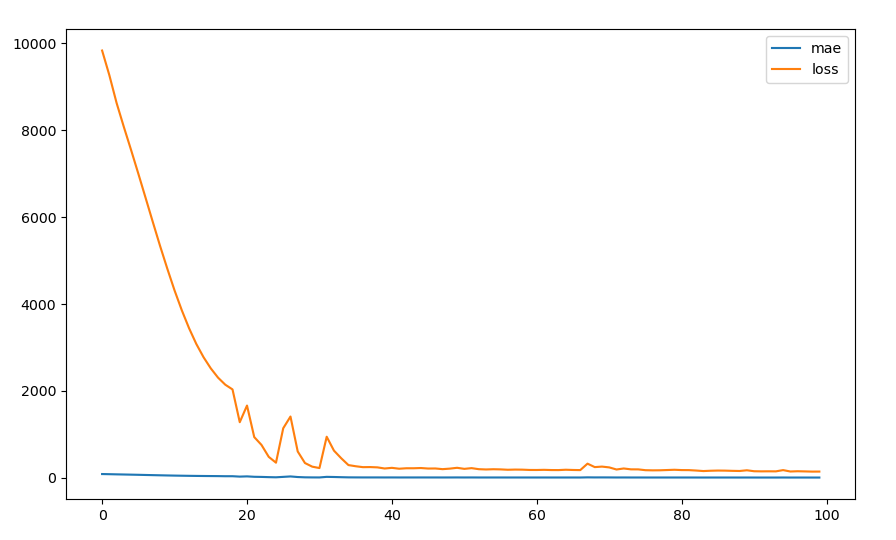
Una volta terminata la fase di trainig, è possibile passare a quella di validazione, utilizzando la seguente linea di codice:
model.evaluate(X_test, y_test, batch_size=6)
In questo caso è stato passato un batch_syze = 6 sui dati di ingresso X_test.
Il risultato ottenuto, anche in questo caso può essere riportato graficamente, mediante le seguenti linee di codice:
# Creazione del grafico
fig, ax = plt.subplots(figsize=(10, 6.10), layout='constrained')
ax.plot(y_test, color="green", marker="s", label='real_test', linestyle="")
ax.plot(v_p, color="red", marker="",label='prediction',linestyle="") ax.plot(e, color="gray", marker="",label='error %',linestyle="-")
ax.set_xlabel('x label') # Add an x-label to the Axes.
ax.set_ylabel('y label')
ax.legend(bbox_to_anchor=(0., 1.05, 1., .102), loc='lower left',
ncols=2, mode="expand", borderaxespad=0.)# Add a legend.
plt.title("Grafico stress events")
plt.xlabel("Number sequences")
plt.ylabel("stress events")
plt.show()
plt.close()
ottenendo, in questo caso, un risultato di questo genere:
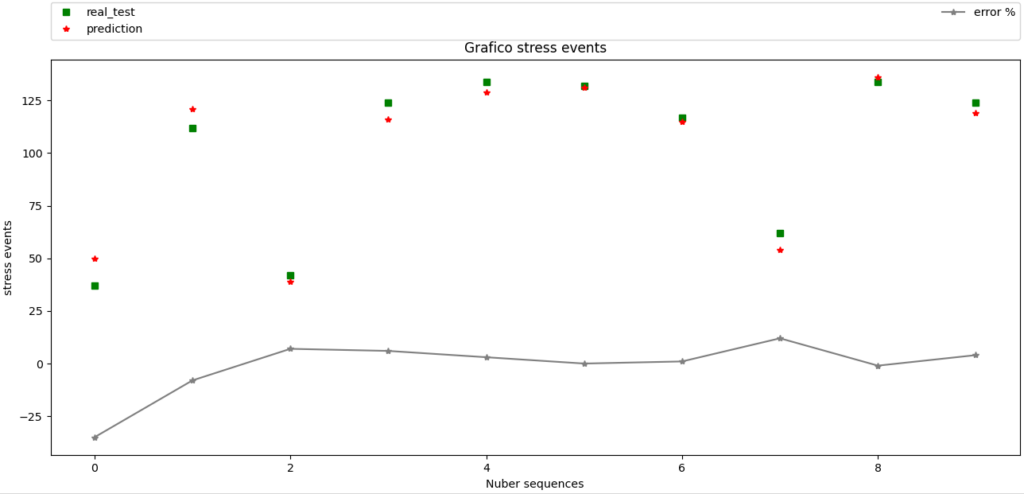
Come si può osservare, il plottaggio è inerente a dei vettori che sono stati ricavati in relazione ai dati prodotti dal modello che, in sostanza, ha elaborato per 100 volte il modello di training e per poche volte il modello di test, come riportato dalle seguenti informazioni copiate dal terminale:
….
Epoch 80/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step – loss: 188.0179 – mae: 10.4328
Epoch 81/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 172.8304 – mae: 10.3376
Epoch 82/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step – loss: 193.7802 – mae: 10.8849
Epoch 83/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 167.6130 – mae: 9.9958
Epoch 84/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step – loss: 168.5521 – mae: 10.0910
Epoch 85/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 166.1593 – mae: 9.9478
Epoch 86/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 181.2276 – mae: 10.3700
Epoch 87/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step – loss: 167.1966 – mae: 10.0520
Epoch 88/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step – loss: 164.8326 – mae: 10.2739
Epoch 89/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 152.0353 – mae: 9.4940
Epoch 90/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 197.9228 – mae: 10.6248
Epoch 91/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 159.9308 – mae: 9.9471
Epoch 92/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 147.8240 – mae: 9.1989
Epoch 93/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 143.6818 – mae: 9.3541
Epoch 94/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 148.8043 – mae: 9.3832
Epoch 95/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 167.6693 – mae: 10.0714
Epoch 96/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 152.4915 – mae: 9.4687
Epoch 97/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 150.1740 – mae: 9.5651
Epoch 98/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 147.2422 – mae: 9.5501
Epoch 99/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 133.1573 – mae: 8.8903
Epoch 100/100
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 11ms/step – loss: 142.7763 – mae: 9.1165
end
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 18ms/step – loss: 78.7232 – mae: 7.1506
Il vettore di ingresso è un vettore trattato da Numpy:
X_test [[2 3 3 … 3 5 3]
[3 4 2 … 5 4 6]
[2 1 5 … 2 2 2]
…
[3 1 1 … 3 5 6]
[4 1 1 … 5 5 4]
[6 2 6 … 5 4 5]]
Il vettore di predizione, è composto da valori floating:
vettore grezzo [[ 47.26421 ]
[127.515976]
[ 33.683308]
[128.81313 ]
[130.34879 ]
[131.35663 ]
[120.9835 ]
[ 58.3758 ]
[131.32555 ]
[106.2321 ]]
che sono stati normalizzati a valori interi mediante la funzione: p = math.floor(y_pred[y_p])
nella procedura di conversione e ricostruzione dei vettori, onde ricavare una serie di valori “delta” indicanti un errore percentuale inerente il valore predetto, per ogni valore calcolato appartenente al vettore y_test, di cui vengono riportate le seguenti linee di codice:
v_p=[]
e=[]
for y_p in range(len(y_pred)):
p = math.floor(y_pred[y_p])
v_p.append(p)
print ("y_test", y_test)
print ("vettore di predizione",v_p)
for d in range(len(y_test)):
delta = ((y_test[d] - v_p[d])/y_test[d])*100
delta= int(delta)
e.append(delta)
print ("vettore delta",e)
Il risultato conseguito in questo caso è il seguente:
y_test [ 37 112 42 124 134 132 117 62 134 124]
vettore di predizione [47, 127, 33, 128, 130, 131, 120, 58, 131, 106]
vettore delta [-27, -13, 21, -3, 2, 0, -2, 6, 2, 14]
Una possibile alternativa di utilizzo inerente questa tipologie di modello è la seguente:
# model = tf.keras.models.Sequential([
# tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1),
# input_shape=[None]),
# #tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(1024, return_sequences=True)),
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(512, return_sequences=True)),
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(256, return_sequences=True)),
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(128, return_sequences=True)),
# tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
# tf.keras.layers.Dense(1),
# ])
#—————————————-
ma è decisamente più impegnativo per la GPU e richiede più tempo di elaborazione.
Linear Regression Model
Un altro modello che vale la pena di testare in questo caso è un predittore che si basa sul concetto statistico di regressione lineare che rappresenta un metodo di stima del valore atteso condizionato di una variabile dipendente Y, dati i valori di altre variabili indipendenti, X 1 , … , X k : E [ Y | X 1 , … , X k ].
In questo caso, verrà utilizzata una variante di questo modello: la regressione lineare multipla (MLR), nota anche semplicemente come regressione multipla.
Questa è una tecnica statistica che utilizza diverse variabili esplicative per prevedere il risultato di una variabile di risposta.
L’obiettivo del MLR è modellare la relazione lineare tra le variabili esplicative (indipendenti) e le variabili di risposta (dipendenti).
In sostanza, la regressione multipla è l’estensione della regressione ordinaria dei minimi quadrati (OLS) perché coinvolge più di una variabile esplicativa.
Formula di calcolo della regressione lineare multipla (MLR) è la seguente:
yi=β0+β1*i1+β2*i2+…+βp*ip+ϵ
dove per i = n osservazioni:
yi= variabile dipendente
xi= variabili esplicative
β0=intercetta y (termine costante)
βp= coefficienti di pendenza per ciascuna variabile
ϵ= termine di errore del modello (noto anche come residui)
La tecnica MLR presuppone che vi sia una relazione lineare tra le variabili dipendenti e indipendenti, che le variabili indipendenti non siano altamente correlate e che la varianza dei residui sia costante.
Il coefficiente di determinazione (R-quadrato) è una metrica statistica che viene utilizzata per misurare la quantità di variazione nel risultato può essere spiegata dalla variazione nelle variabili indipendenti.
R2 aumenta sempre man mano che più predittori vengono aggiunti al modello MLR, anche se i predittori potrebbero non essere correlati alla variabile di risultato.
Questo modelle viene utilizzato per determinare una relazione matematica tra diverse variabili casuali.
In altri termini, MLR esamina come più variabili indipendenti sono correlate a una variabile dipendente.
Una volta che ciascuno dei fattori indipendenti è stato determinato per prevedere la variabile dipendente, le informazioni sulle variabili multiple possono essere utilizzate per creare una previsione accurata sul livello di effetto che hanno sulla variabile di risultato.
Il modello crea una relazione sotto forma di una linea retta (lineare) che si avvicina meglio a tutti i singoli punti dati, questo difatti però limita la sua precisione nella predizione nel caso a cui lo vogliamo sottoporre, se ben ci pensate!
Comunque sia vediamo la costituzione (più semplice) di tale modello:
Il codice per Linear Regression Model:
def LR():
print(“START LINEAR REGRESSION”)
global X_train, y_train, X_test, y_test
import numpy as np
import math
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
## Creiamo un semplice dataset
# train_gen()
X= X_train
y = y_train
#y=ds
print(“*************************”)
#print (“X=”, X)
#print(“***”)
#print(“stress array di train”, y)
# # Inizializziamo e addestriamo il modello
model_multi = LinearRegression()
model_multi.fit(X, y)
y_pred = model_multi.predict(X)
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print(f’MSE: {mse}’)
print(f’R-squared: {r2}’)
print(“—————–“)
# # # Otteniamo i coefficienti
intercept_multi = model_multi.intercept_
coefficients_multi = model_multi.coef_
print(f’Intercetta (β₀): {intercept_multi}’)
print(f’Coefficiente β₁: {coefficients_multi[0]}’)
print(f’Coefficiente β₂: {coefficients_multi[1]}’)
print(“——————-“)
#—————-
n_k =[]
e=[]
num_test = len(y_test)
for n in range(num_test):
X = X_test[n]
print (“X=”,X)
print(“stress_test=”,y_test[n])
k= model_multi.predict([X])
print (“stress presunto=”,k)
n_k.append(k)
delta = ((y_test[n] – k)/y_test[n])*100
e.append(delta)
#——————–
print (“vettore calcolato di test per stress”, y_test)
print (“risultato delle predizioni”, n_k)
#—————————————————–
# Creazione del grafico
fig, ax = plt.subplots(figsize=(10, 6.10), layout=’constrained’)
# #ax.plot(ds, color=”blue”, marker=”o”, label= ‘train stress’, linestyle=””)
ax.plot(y_test, color=”green”, marker=”s”, label=’real_test’, linestyle=””)
ax.plot(n_k, color=”red”, marker=”*”,label=’prediction’,linestyle=””)
ax.plot(k, color=”red”, marker=”*”,label=’prediction’,linestyle=””)
ax.plot(e, color=”gray”, marker=”*”,label=’error %’,linestyle=”-“)
# ## plt.scatter(x,yO, s=15, c=colors, cmap=”Blues”) # funziona solo se richiamata singola e non in sequenza
# ## cbar = plt.colorbar()
# ## cbar.set_label(“type_stress”)
ax.set_xlabel(‘x label’) # Add an x-label to the Axes.
ax.set_ylabel(‘y label’)
ax.legend(bbox_to_anchor=(0., 1.05, 1., .102), loc=’lower left’,
ncols=2, mode=”expand”, borderaxespad=0.)# Add a legend.
plt.title(“Grafico stress events”)
plt.xlabel(“Number sequences”)
plt.ylabel(“stress events”)
plt.show(block=False)
plt.pause(100)
plt.close()
#—————
da precisare che questo modello utilizza una libreria particolare, importata nel codice Python con le seguenti istruzioni:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
Scikit-learn è sicuramente una delle più importanti librerie di Python per il Machine Learning.
Questa libreria è totalmente gratuita, open source e costantemente aggiornata da una vasta comunità internazionale di tecnici.
Scikit-learn si inserisce perfettamente in questo contesto fornendo una vasta gamma di algoritmi di apprendimento automatico per classificazione, regressione, clustering ecc.
Scikit-learn rappresenta dunque uno strumento potente e flessibile per sviluppare soluzioni di apprendimento automatico.
La sua facilità d’uso e l’ampia gamma di funzionalità la rendono ideale per una vasta gamma di applicazioni nel campo dell’intelligenza artificiale, e quindi mi sembrava opportuno testarne alcune.
Il risultato ottenuto da questo modello, in questo caso, si basa sui parametri riportati a terminale:
START LINEAR REGRESSION
MSE: 102.35064800959468
R-squared: 0.9418871294280144
Intercetta (β₀): -147.2268254762597
Coefficiente β₁: -0.1065681845316534
Coefficiente β₂: -0.23586994510034032
dove MSE indica il “Mean squared error” ed R2indica il coefficiente di determinazione (il punteggio del modello di regressione) che, tanto per renderne l’idea, nella MLR ha un comportamento del genere:
y_true = [[0.5, 1], [-1, 1], [7, -6]]
y_pred = [[0, 2], [-1, 2], [8, -5]]
r2_score(y_true, y_pred, multioutput=’variance_weighted’)
0.938…
Tenendo conto che nel caso in esame la situazione, per ogni vettore in ingresso sarebbe qualcosa di questo tipo:
X= [6 2 6 1 3 4 5 2 1 6 4 2 3 3 2 1 6 3 6 2 1 3 5 4 1 3 6 1 1 1 4 2 6 4 5 1 5 6 4 3 5 4 6 2 2 5 6 2 3 4 4 5 1 1 1 2 2 2 2 5 2 5 2 2 4 4 4 3 6 3 3 1 1 3 1 4 1 4 2 4 2 1 3 5 4 3 6 4 3 2 3 1 4 6 2 4 2 6 5 1 6 2 4 5 6 5 6 4 6 5 11 5 6 6 6 6 4 4 1 6 5 4 6 1 5 6 1 4 4 4 1 5 5 6 1 4 5 6 6 5 4 4 4 5 6 6 4 5 6 5 5 6 4 5 4 4 6 4 4 4 4 4 6 4 6 5 4 5 4 6 6 5 4 4 5 6 6 5 6 6 4 5 4 6 6 5 4 5 6 5 6 5 6 5 6 4 6 4 5 5 6 6 6 6 5 4 4 5 4 5 6 4 6 5 6 6 4 6 4 4 4 6 6 6 5 4 4 5 5 4 4 5 4 5 5 5 5 5 4 6 5 4 4 4 5 5 4 5 6 5 5 5 6 5 6 5 5 5 5 6 6 6 6 5 5 5 5 6 6 6 5 5 6 5 6 6 6 5 6 6 5 5 5 6 6 6 5 5 5 6 6 5 6 5 6 5 5 5 5 6 6 6 6 6 6 6 5 6 6 6 6 5 6 5 5 5 5 2 3 6 5 3 2 6 5 2 4 2 3 6 5 3 4 2 5 3 5 6 5 4 2 2 5 3 6 6 4 5 5 3 6 6 5 6 3 4 5 4 5]
stress_test= 124
stress presunto= [113.3332015]
in questo caso dunque, l’output grafico è il seguente:
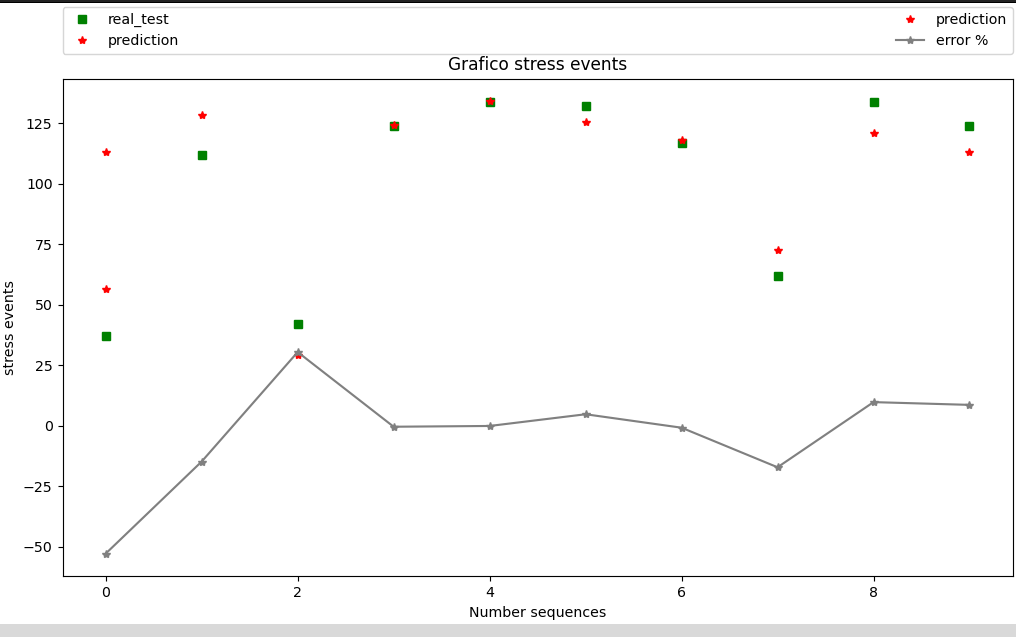
dove il vettore calcolato di test per stress:
(y_test) = [ 37 112 42 124 134 132 117 62 134 124]
mentre il “vettore grezzo” di output del modello è il risultato delle predizioni:
[array([56.57256574]), array([128.59989617]), array([29.2146974]), array([124.54476604]), array([134.16260022]), array([125.76638144]), array([117.98344887]), array([72.66654165]), array([120.94963311]), array([113.3332015])]
che ovviamente è stato opportunamente trattato per calcolarne la funzione “delta”, come riportato dalle istruzioni:n_k =[]
e=[]
num_test = len(y_test)
for n in range(num_test):
X = X_test[n]
print ("X=",X)
print("stress_test=",y_test[n])
k= model_multi.predict([X])
print ("stress presunto=",k)
n_k.append(k)
delta = ((y_test[n] - k)/y_test[n])*100
e.append(delta)
Ma ci sono altri modelli da testare utilizzando il machine learning.
Decision Trees Model
Gli “alberi decisionali” (Dts), sono un metodo di apprendimento supervisionato non parametrico utilizzato per la classificazione e la regressione.
L’obiettivo è creare un modello che preveda il valore di una variabile target apprendendo semplici regole di decisione dedotte dalle caratteristiche dei dati.
Un albero può essere visto come un’approssimazione costante a tratti.
Alcuni vantaggi degli alberi decisionali potrebbero essere dati in riferimento alle seguenti constatazioni:
- Questo è un modello relativamente semplice da capire e interpretare, gli alberi possono essere visualizzati.
- Richiede poca preparazione dei dati, altre tecniche richiedono spesso la normalizzazione dei dati, è necessario creare variabili fittizie e valori vuoti da rimuovere. (Alcune combinazioni di alberi e algoritmi supportano valori mancanti).
- Il “costo dell’utilizzo” dell’albero (cioè prevedere i dati) è logaritmico nel numero di punti dati utilizzati per addestrare l’albero.
- Questo modello potrebbe essere in grado di gestire i dati sia numerici che categorici. Tuttavia, l’implementazione di Scikit-Learn non supporta le variabili categoriche per ora.
- Questo modello è in grado di gestire problemi multi-output.
- Questo è un modello che utilizza un logica esplicita o definibile come “scatola bianca”. Se una determinata situazione è osservabile in un modello, la spiegazione della condizione è facilmente spiegata dalla logica booleana. Al contrario, in un modello di scatola nera (ad es. in una rete neurale artificiale), i risultati possono essere più difficilmente interpretabili.
- Vi è la Possibilità di convalidare un modello usando test statistici. Ciò consente di tenere conto dell’affidabilità del modello.
- E’ un modello che si comporta bene anche se i suoi presupposti sono in qualche modo violati dal vero modello da cui sono stati generati i dati.
Ma vediamo il codice per l’utilizzo di questo modello:
Codice Python per Decision Tree Model
# analisi vettoriale nota: porta al grafico
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import os
# print("Current working directory: {0}".format(os.getcwd()))
#os.chdir('/home/romeo/2025/2025_python/MWS')
# print("Current working directory: {0}".format(os.getcwd()))
# datset train extaction
train_set = pd.read_csv("Train_seq_num.csv", header = None)
# print(“train_set “,train_set.head(3))
# print(“len columns “,len(train_set.columns))
# print(“last columns”, train_set[360]) # stress vector
trv_s = np.array(train_set[360])
#print (“train_vector_stress”, train_vector_stress)
vtr_g=np.array(train_set)
#print(“len vtrg”,len(vtr_g))
vtr= vtr_g[0]
vtr = vtr[:-1]
vtr= vtr_g[len(trv_s)-1]
vtr = vtr[:-1]
#print(“ultimo vettore”, vtr)
tr_v=[]
for tr in range (len(trv_s)):
vtr= vtr_g[tr]
vtr = vtr[:-1]
tr_v.append(vtr)
#————————–
X_train = tr_v
y_train = trv_s
#————————–
# datset test extaction
test_set = pd.read_csv("Test_seq_num.csv", header = None)
# print(“test_set “,test_set.head())
# print(“len columns “,len(test_set.columns))
# print(“last columns”, test_set[360]) # stress vector
tev_s = np.array(test_set[360])
#print (“train_vector_stress”, train_vector_stress)
vte_g=np.array(test_set)
#print(“len vte_g”,len(vte_g))
vte= vte_g[0]
vte = vte[:-1]
#——
#print(“len_vte=”,len(vte))
#print(“len_stress_v_test=”,len(tev_s))
#print(“primo vettore”, vtr)
vte= vte_g[len(tev_s)-1]
vte = vte[:-1]
#print(“ultimo vettore”, vtr)
te_v=[]
for te in range (len(tev_s)):
vte= vte_g[te]
vte= vte[:-1]
te_v.append(vte)
#print(“len_te_v”, len(te_v))
#————————–
X_test = te_v
y_test = tev_s
#print (“te_v”, te_v)
#print (“te_s”, tev_s)
#*********************************#
import sklearn
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
model_one = sklearn.tree.DecisionTreeClassifier()
model_one.fit(X_train,y_train)
pr1 = model_one.predict(X_test)
print(“————————-“)
#—————-
n_k =[]
e=[]
num_test = len(y_test)
for n in range(num_test):
delta = ((y_test[n] - pr1[n])/y_test[n])*100
e.append(delta)
#——————
tree.plot_tree(model_one)
# Creazione del grafico
fig, ax = plt.subplots(figsize=(10, 6.10), layout='constrained')
ax.plot(y_test, color="green", marker="s", label='real_test', linestyle="")
ax.plot(pr1, color="red", marker="",label='prediction',linestyle="") ax.plot(e, color="gray", marker="",label='error %',linestyle="-")
ax.set_xlabel('x label') # Add an x-label to the Axes.
ax.set_ylabel('y label')
ax.legend(bbox_to_anchor=(0., 1.05, 1., .102), loc='lower left',
ncols=2, mode="expand", borderaxespad=0.)# Add a legend.
plt.title("Grafico stress events")
plt.xlabel("Number sequences")
plt.ylabel("stress events")
plt.show(block=False)
plt.pause(100)
plt.close()
print ("vettore calcolato di test per stress", y_test)
print ("risultato delle predizioni", pr1)
Il codice è completo della parte di estrazione dei dati effettuata con Pandas.
Output grafici:
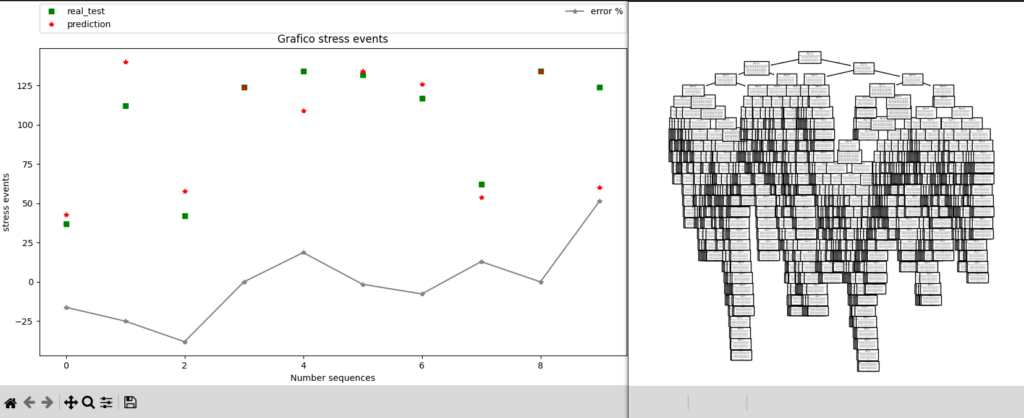
Come si può notare, è possibile anche stampare l’albero generato!
Output a terminale:
vettore calcolato di test per stress [ 37 112 42 124 134 132 117 62 134 124]
risultato delle predizioni [ 43 120 45 136 138 107 124 54 120 60]
I modelli KNN
L’algoritmo k-nearest neighbors (KNN) è un classificatore di apprendimento supervisionato non parametrico, che utilizza la prossimità per effettuare classificazioni o previsioni sul raggruppamento di un singolo punto dati.
Si tratta di uno dei più popolari e semplici attualmente utilizzato nell’apprendimento automatico ed ha anche una versione che lo impiega come algoritmo di regressione.
Sebbene l’algoritmo KNN possa essere utilizzato sia per problemi di regressione che di classificazione, solitamente viene usato come algoritmo di classificazione, partendo dal presupposto che punti simili possano essere trovati vicini l’uno all’altro.
I problemi di regressione utilizzano un concetto simile a quello di classificazione, ma in questo caso la media dei “k” vicini più prossimi viene presa in considerazione per fare una previsione su una classificazione.
La distinzione principale qui è che, la classificazione viene utilizzata per i valori discreti, mentre la regressione viene utilizzata per quelli continui.
Tuttavia, prima di poter effettuare una classificazione, è necessario definire la distanza.
La distanza euclidea è quella più comunemente utilizzata.
Il codice per i due modelli KNN utilizzati è il seguente:
Codice per KNN_R e per KNN_C
import sklearn
from sklearn import tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn import neighbors
model_two = sklearn.neighbors.KNeighborsClassifier()
model_two.fit(X_train,y_train)
pr2 = model_two.predict(X_test)
print("-------------------------")
n_neighbors = 1
y_p =[]
for i, weights in enumerate(["uniform", "distance"]):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_pred = knn.fit(X_train, y_train).predict(X_test)
y_p.append(y_pred)-
knrp=[]
for y_p in range(len(y_pred)):
p = math.floor(y_pred[y_p])
knrp.append(p)
n_k =[]
e=[]
e1=[]
num_test = len(y_test)
for n in range(num_test):
delta = ((y_test[n] - pr2[n])/y_test[n])100 delta1 = ((y_test[n] - knrp[n])/y_test[n])100
e.append(delta)
e1.append(delta1)
fig, ax = plt.subplots(figsize=(10, 6.10), layout='constrained')
ax.plot(y_test, color="green", marker="s", label='real_test', linestyle="")
ax.plot(knrp, color="magenta", marker="", label='KnR_pred', linestyle="") ax.plot(pr2, color="red", marker="",label='KnC_pred',linestyle="")
ax.plot(e, color="red", marker="",label='error_KnC %',linestyle="-") ax.plot(e1, color="magenta", marker="",label='error_KnR %',linestyle="-")
ax.set_xlabel('x label') # Add an x-label to the Axes.
ax.set_ylabel('y label')
ax.legend(bbox_to_anchor=(0., 1.05, 1., .102), loc='lower left',
ncols=2, mode="expand", borderaxespad=0.)# Add a legend.
plt.title("Grafico stress events")
plt.xlabel("Number sequences")
plt.ylabel("stress events")
plt.show(block=False)
plt.pause(100)
plt.close()
#---------------------
print ("vettore calcolato di test per stress", y_test)
print ("y_p", knrp)
print ("pr2", pr2)
Output grafico:
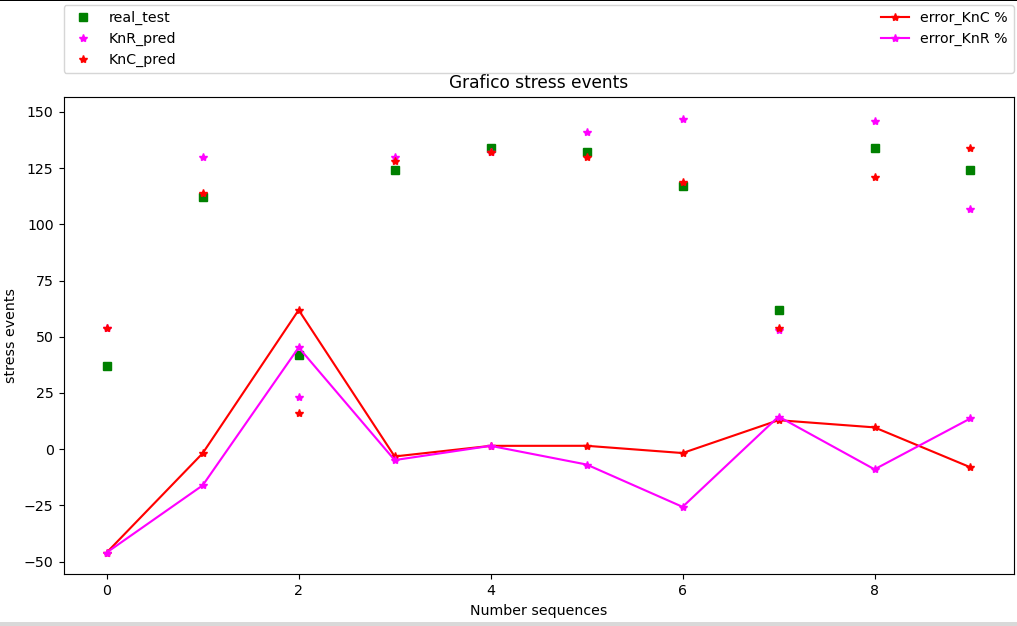
Interessante notare che l’algoritmo classificatore, sembra avere una performance leggermente migliore del regressore, ma in questo caso, invito il lettore a fare delle prove ulteriori.
output a terminale:
vettore calcolato di test per stress [ 37 112 42 124 134 132 117 62 134 124]
y_p [54, 130, 23, 130, 132, 141, 147, 53, 146, 107]
pr2 [ 54 114 16 128 132 130 119 54 121 134]
Un altro modello da prendere in considerazione potrebbe essere anche quello definito come il modello a regressione logistica che è anche questo un modello di classificazione.
Viene usato nel machine learning per addestrare un algoritmo a classificare correttamente i dati.
Si tratta di un modello lineare di classificazione binaria o multiclasse.
Il modello LLR (LinearLogisticRegression)
Sia la regressione lineare che la regressione logistica utilizzano modelli matematici per prevedere il valore di una variabile di output da una o più variabili di input.
Per la regressione lineare, ogni variabile indipendente ha una relazione diretta con la variabile dipendente e non ha alcuna relazione con le altre variabili indipendenti.
Questa relazione è nota come relazione lineare.
La variabile dipendente è in genere un valore compreso in un intervallo di valori continui.
Questa è la formula, o funzione lineare, per creare un modello di regressione lineare:
y= β0 + β1X1 + β2X2+… βnXn+ ε
Ecco cosa significa ogni variabile:
- y è la variabile dipendente prevista
- β0 è l’intercetta y quando tutte le variabili di input indipendenti sono uguali a 0
- β1X1 è il coefficiente di regressione (B1) della prima variabile indipendente (X1), il valore di impatto della prima variabile indipendente sulla variabile dipendente
- βnXn è il coefficiente di regressione (BN) dell’ultima variabile indipendente (XN), quando ci sono più valori di input
- ε è l’errore del modello
Per la regressione logistica, invece, il valore della variabile dipendente proviene da un elenco di categorie finite che utilizzano la classificazione binaria.
Queste sono dette variabili categoriali.
Un esempio è il risultato del lancio di un dado a sei facce.
Questa relazione è nota come relazione logistica.
La formula per la regressione logistica applica una trasformazione “logit”, o il logaritmo naturale delle probabilità, alla probabilità di successo o fallimento di una particolare variabile categoriale.
In questo caso la formula è la seguente:
y = e^(β0 + β1X1 + β2X2+… βnXn+ ε) / (1 + e^(β0 + β1 x 1 + β2 x 2 +… βn x n + ε))
Ecco cosa significa ogni variabile:
- y dà la probabilità di successo della variabile categoriale y
- e (x) è il numero di Eulero, l’inverso della funzione logaritmica naturale o della funzione sigmoide, ln (x)
- β0, β1X1… βnXn hanno lo stesso significato della regressione lineare nella sezione precedente.
Bisogna comunque sottolineare che un modello statistico che adatta i dati di input ai dati di output non implica necessariamente una relazione causale tra la variabile dipendente e quella indipendente. Sia per la regressione logistica che per la regressione lineare, la correlazione non è causalità.
In qualsiasi caso, l’output di una regressione lineare consiste in una scala di valori continui (numeri a virgola mobile o floating numbers) mentre l‘output numerico della regressione logistica, che è la probabilità prevista, può essere utilizzato come classificatore applicando una soglia (per impostazione predefinita 0,5).
È così che viene implementato in Scikit-Learn, quindi si aspetta un obiettivo categorico, rendendo la regressione logistica un classificatore.
Il codice per la LLR
import sklearn
from sklearn import tree
from sklearn.neighbors import KNeighborsClassifier
model_three = sklearn.linear_model.LogisticRegression()
model_three.fit(X_train,y_train)
pr3 = model_three.predict(X_test)
print("-------------------------")
#—————-
n_k =[]
e=[]
num_test = len(y_test)
for n in range(num_test):
delta = ((y_test[n] - pr3[n])/y_test[n])*100
e.append(delta)
#——————
#Creazione del grafico
fig, ax = plt.subplots(figsize=(10, 6.10), layout='constrained')
ax.plot(y_test, color="green", marker="s", label='real_test', linestyle="")
ax.plot(pr3, color="red", marker="",label='prediction',linestyle="") ax.plot(e, color="gray", marker="",label='error %',linestyle="-")
ax.set_xlabel('x label') # Add an x-label to the Axes.
ax.set_ylabel('y label')
ax.legend(bbox_to_anchor=(0., 1.05, 1., .102), loc='lower left',
ncols=2, mode="expand", borderaxespad=0.)# Add a legend.
plt.title("Grafico stress events")
plt.xlabel("Number sequences")
plt.ylabel("stress events")
plt.show(block=False)
plt.pause(100)
plt.close()
#———————
print ("vettore calcolato di test per stress", y_test)
print ("risultato delle predizioni", pr3)
Output Grafico:
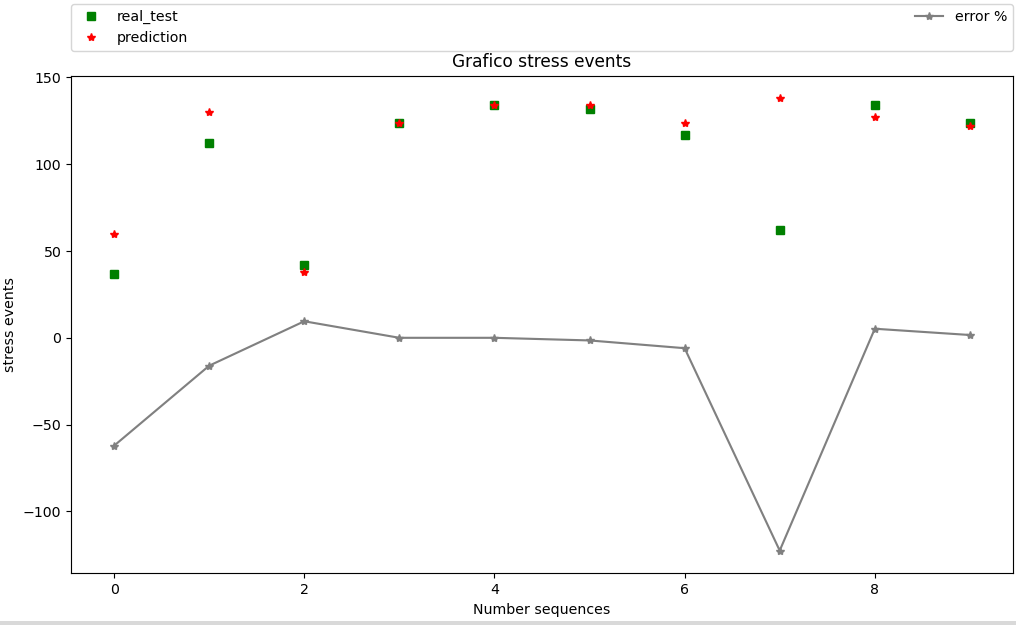
output a terminale:
vettore calcolato di test per stress [ 37 112 42 124 134 132 117 62 134 124]
risultato delle predizioni [ 60 130 38 124 134 134 124 138 127 122]
Conclusioni
A questo punto, non mi resta che invitare il lettore ad esplorare il mondo del Machine Learning e del Deep Learning, per cercare ulteriori sistemi di previsione giocando sull’analisi delle sequenze, anche in considerazione del fatto che ci possono essere multi campi di applicazione dove l’intelligenza artificiale può essere impiegata in sistemi di misure, monitoraggio e controllo.
A tal proposito, invito coloro che volessero approfondire ulteriormente questi temi, specialmente se interessati ad orientarsi nel mondo delle nuove professioni, dove sono basilari determinate competenze scientifiche a leggere il mio libro MMS: Misure Monitoraggio Controllo, un testo concepito per la divulgazione scientifica a carattere didattico,
Questo libro tratta argomentazioni quali la sensoristica vegetale ed animale come base di partenza per poi svilupparsi nell’ambito dei processi di misura, monitoraggio e controllo, spaziando tra vari contesti, quali l’informatica, la fisica e la medicina, trattando inoltre, argomentazioni di cibernetica e intelligenza artificiale, con una particolare attenzione alla concettualistica matematica fondamentale inerente questo contesto.
Un libro, scritto con la passione di chi, sin da giovane, ha usato il motore della curiosità, per percorrere i sentieri che la vita gli ha donato, al fine di cercare di comprendere, quanto più possibile, il gioco delle dinamiche che governano gli eventi. Un libro nel quale sono stati raccolti, come doni universali, alcuni dei più bei frutti del lavoro di menti eccelse. Un libro per tutti coloro che, a vario titolo, possono essere attratti da argomentazioni scientifiche, ma che può essere particolarmente indicato come punto di riferimento per gli studenti che si approcciano agli studi delle nuove professioni, che implicano un approccio multidisciplinare e polifunzionale, come sottinteso dall’acronimo STEM, (science, technology, engineering and mathematics).

A proposito, in ambito di monitoraggio e controllo negli ambienti di lavoro, per determinate mansioni, come quella degli “Stower” o dei “Picker”, che debbono seguire le sequenze dettate da un algoritmo, sarebbe bello se si potessero evitare ripetizioni di sequenze ad alto valore di “Stress”, così come sarebbe bello, al termine del turno di lavoro, ricevere una domanda sul livello di stress accumulato, magari cliccando su una “emoticon” appropriata, così almeno si potrebbe dare adito ad una sistema di controllo a “Catena Chiusa”.
Buona lettura
Romeo Ceccato