introduzione
Il titolo è sicuramente ironico, ma lo ho scritto perché in questo articolo, vorrei descrivere senza entrare in tecnicismi noiosi, poiché mi vorrei rivolgere anche a persone non del settore, o a coloro che, mossi dalla curiosità, vogliono fare qualche esperienza nel settore della “gestione digitale delle informazioni”, “giovani studenti” o “vecchi hobbisti”, che utilizzano internet, anche per apprendere qualcosa che non hanno avuto modo di approfondire nel loro percorso culturale.
Quattro chiacchiere “all’Internet Bar”, tra amici insomma, tanto per passare un po’ di tempo assieme, davanti ad un buon bicchiere, guardando i “Bit” che passano per strada.

Già, Internet potrebbe essere proprio come una immensa metropoli, piena di strade ad alta percorrenza, viali, vicoli, vie e viuzze, che portano a case, condomini, palazzi e grattacieli pieni di appartamenti, uffici, negozi, ristoranti e bar, vari locali pieni di attrazioni, musei, biblioteche, fino alle grandi fabbriche della periferia, tutti con un loro specifico indirizzo univoco, qualcosa di “Protocollato”, che identifichi, nella maniera più semplice possibile, quel particolare “numero civico”, a cui far confluire i flussi di dati, composti proprio dai bit, ma che possa anche essere “configurato dinamicamente”, per rispettare le dinamiche di una tale immensa metropoli, sempre in evoluzione.
Gli indirizzi IP
Un indirizzo IP (Internet Protocol) è dunque un’etichetta numerica univoca assegnata a ogni “dispositivo” connesso le vie di comunicazione di Internet.
Questo indirizzo serve a due funzioni principali: identificare il “dispositivo” e localizzarlo.
Gli indirizzi IP pertanto, sono come gli indirizzi postali, che permettono ai pacchetti di dati di trovare la destinazione giusta (via e numero civico), ed anche il soggetto a cui sono destinati.
La nascita di un “protocollo internet” avvenne nel 1981 con la pubblicazione dell’RFC (“Request for Comments“) 791, documento fondamentale che definisce il protocollo di rete IP, elaborato da parte della IETF (Internet Engineering Task Force) ed utilizza indirizzi a 32 bit, rappresentati da quattro numeri decimali separati da punti (es. 192.168.1.1), che consentivano circa 4,3 miliardi di indirizzi unici, che per l’epoca, sembravano moltissimi, ma, vista l’evoluzione tecnologica, e la rapida crescita di Internet si è resa necessaria l’adozione del successore, IPv6, a partire dalla fine degli anni ’90.
L’IPv6 è nato ufficialmente come standard nel 1998 per risolvere la crisi di esaurimento degli indirizzi IP, ma la sua introduzione pratica è stata graduale, con il primo tunnel in Italia nel 1999 e l’implementazione sui “server root” nel 2004, segnando l’inizio dell’era di una maggiore disponibilità di indirizzi per Internet.
L’IPv6 è un formato esadecimale separato da due punti (es. 2001:db8:0:1234:0:567:8:1). Si passa dunque da 32bit a 128 bit, offrendo un numero quasi illimitato di indirizzi per supportare la crescita esponenziale dei dispositivi connessi (IoT ,alias diInternet of Things, o “Internet delle Cose”).
Tipi di indirizzi IP
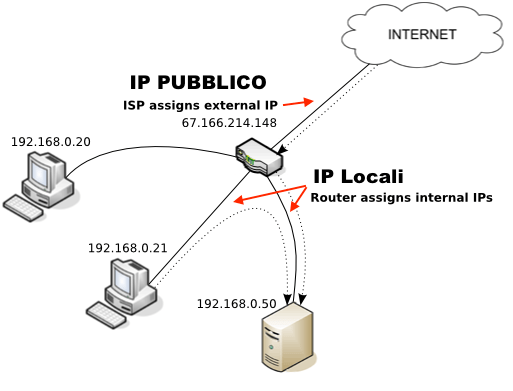
IP Pubblico: l’indirizzo IP pubblico è quello che viene assegnato dal provider di servizi Internet (ISP) e permette ai dispositivi esterni di comunicare con la rete pubblica.
IP Privato: all’interno della rete domestica, invece, il “router” assegna indirizzi IP privati unici a ciascun dispositivo connesso (quindi ad ognuno il suo IP identificativo unico, privato!).
Questi non sono visibili al di fuori della rete.
IP Statico: un indirizzo che non cambia nel tempo, è utile per i dispositivi che devono essere sempre raggiungibili, come i “server”.
IP Dinamico: un indirizzo che può cambiare nel tempo e viene assegnato dinamicamente a un dispositivo, ad esempio, quando ci si connette a una rete Wi-Fi pubblica.
Le reti informatiche
Le vie di percorrenza dei dati vengono definite come “Reti”, ve ne sono di tipologie diverse, molti dicono che internet si possa definire anche come “la rete delle reti”, a livello planetario, un intricato sistema di connessioni, di dispositivi e di circuiti che servono a scambiare dati di tutti i tipi, ma sempre a carattere digitale, qualche cosa di molto complesso che serve da strumento globale per facilitare la comunicazione che senza dubbio è l’attività più diffusa su questo pianeta abitato da vegetali, animali, umani, macchine e chissà cos’altro, è la generazione di informazioni, che comprende la loro comunicazione e la loro interpretazione, mediante i processi di ricezione.
Per quanto riguarda i manufatti e gli umani, negli ultimi tempi il sistema più usato per la comunicazione è la trasmissione / ricezione digitale dei dati, la comunicazione digitale si basa su delle reti informatiche e reti informatiche sono composte da un insieme di apparati hardware che utilizzano dei software, e sono tra loro collegati, attraverso determinati canali di comunicazione, atti a gestire la trasmissione / ricezione di dati costituenti le informazioni.
Il concetto di informazione
“In forma azione”, anche senza scomodare antiche lingue per trarne l’etimologia, la scomposizione della parola “informazione” suggerisce che si tratta di qualche cosa che può servire a “dare forma”, qualche cosa che viene scambiata per essere in qualche modo utilizzata.
Da quanto sopra, si può allora dedurre che l’informazione sia una “grandezza misurabile”, o meglio, “quantizzabile”.
Per la nostra comunicazione scritta, noi usiamo dei simboli, che sono le “particelle elementari” di un linguaggio, sembra logico quindi pensare che ogni singola particella, abbia un contenuto informatico distinguibile da ogni altra particella di quel linguaggio.
Ma una qualsiasi informazione ha un suo significato di esistenza se e solo se, viene quantomeno trasmessa.
Potremmo dire che, se qualche cosa “esiste”, non può “non comunicare”, ma allora, il concetto di informazione prende significato appunto se correlato alla comunicazione.
Quindi, secondo la “Teoria della informazione”, in una comunicazione, costituita da un segnale correlato ad un linguaggio considerato come un insieme finito di oggetti trasmissibili con simboli discrezionali, l’informazione viene associata a ciascun simbolo trasmesso e viene definita come la riduzione di incertezza che si poteva avere a priori sul simbolo trasmesso.
In particolare, la quantità di informazione correlata a un simbolo è definita come:
I = – log2 Pi
dove Piè la “probabilità” di trasmissione di quel simbolo.
La quantità di informazione associata a un simbolo è misurata in bit.
La quantità di informazione così definita è quindi una variabile aleatoria discreta, il cui valore medio, tipicamente riferito alla “sorgente di simboli”, è detto entropia della sorgente, ed è misurata in “bit/simbolo”.
L’entropia della sorgente è per definizione pari alla sommatoria, estesa a tutti i simboli della sorgente, dei prodotti tra la probabilità di ciascun simbolo e il suo contenuto informativo.
Dalla formula si evince in particolare che se la probabilità Pi di trasmettere il simbolo è pari a uno, la quantità di informazione associata è nulla; viceversa se nel caso limite ideale di “Pi=0” la quantità di informazione sarebbe infinita.
Da quanto sopra si evince la profondità filosofica che può assumere tale teoria, che evidentemente ha delle correlazioni matematico-fisiche molto più ampie da quelle sintetizzate in questa esposizione e che invito ad approfondire, partendo magari dallo studio di filosofi come Platone ed Aristotele, per arrivare magari al “modello di Shannon e Weaver”, alla teoria delle “Basi di dati” e al “Modello relazionale”.
La comunicazione
La velocità di informazione di una sorgente, che non coincide con la frequenza di emissione dei simboli, dato che non è detto che ogni simbolo trasporti un bit di informazione “utile”, è il prodotto dell’entropia dei simboli emessi dalla sorgente per la frequenza di emissione di tali simboli (velocità di segnalazione).
Una delle principali problematiche della comunicazione è la “codifica dei dati”, intendendo, con questo termine, la potenzialità di trasformare un’informazione generica in un’informazione comprensibile.
Questa operazione è difficile anche per gli umani che parlano la stessa lingua, figuriamoci se si tratta di implementare questa capacità a dispositivi che devono implementare elaborazioni informatiche.
Il primo problema da affrontare nei processi di elaborazione dell’informazione è la rappresentazione dell’informazione.
L’informazione consiste nella possibilità di trasmissione e ricezione di un messaggio tra un insieme di possibili messaggi, quindi la definizione esatta è che l’informazione si rappresenta usando un numero finito di simboli affidabili e facilmente distinguibili.
Per quanto concerne le apparecchiature digitali, l’informazione è rappresentata mediante livelli di tensione o mediante magnetizzazione di dispositivi appropriati (memorie di massa ecc.).
Le esigenze di affidabilità impongono che tali simboli, per una maggiore efficienza, siano tre:
- 2 livelli di tensione esempio standard TTL: 0/5 V; standard RS-232: +12/-12 V, che vanno a formare la numerazione binaria; (modulazioni in frequenza, modulazioni in ampiezza, modulazioni di fase)
- HiZ (alta impedenza), che rappresenta un livello indeterminato, causato ad esempio dal filo “scollegato”, (assenza di segnale portante).
Le informazioni viaggiano su “canali”, e ad ogni canale è attribuibile una “potenzialità di trasmissione / ricezione dei dati, che è indipendente dalla velocità di trasmissione, ma dalla quantità di trasmissione contemporanea dei dati trasmessi, per analogia, si pensi ai canali di irrigazione, o alle condotte d’acqua.
Un canale può essere costituito almeno da una trasmittente ed una ricevente ed un supporto di comunicazione.
La comunicazione dei dati quindi può avvenire con delle modalità diverse:
- “simplex”, quando il messaggio viene inviato attraverso un solo passaggio;
- “half duplex”, quando la comunicazione avviene in entrambi i sensi, ma in tempi differenti;
- “full duplex”, quando la trasmissione avviene in entrambe le direzioni contemporaneamente.
E’ vero altresì che ci si può trovare di fronte ad altre situazioni, come quella che vede un insegnante che comunica a degli allievi, dove una sorgente comunica a molti (o a tutti quelli che fanno parte della sua rete di comunicazione).
Oppure dove molti comunicano ad una sola potenziale ricevente, caso molto più raro apparentemente per gli esseri umani, ma che può essere inteso come una sessione di preghiera comunitaria, cosa invece che avviene comunemente per i sistemi automatizzati di comunicazione, dove molti “host” o “client”, comunicano con un “server”, come al bar!
Infine, la situazione di “comunicazione globale”, dove tutti comunicano con tutti… magari contemporaneamente, questa si, una condizione utopica! Ma che presenta delle bellissime considerazioni da poter essere meglio approfondite in termini filosofici.
I messaggi, o codici interpretabili, comunicati e ricevuti che siano stati interpretati o meno, costituiscono quindi il materiale di scambio delle reti informatiche.
Ci sono due casi particolari da considerare, uno, riguarda la fonte di comunicazione, nel caso sfortuito che generasse della comunicazione “a vuoto”, dove il suo messaggio non trova nessuna ricevente disponibile, e l’altro, una ricevente esistente che non riceve nessun messaggio, che sia interpretabile o meno!
Questi sono dei casi limite, che possono essere dei problemi per le comunicazioni animali, ma non lo costituiscono per le comunicazioni di automi, se non per il fatto che, in mancanza di alimentazione energetica, questi finirebbero per ottemperare al loro compito.
Un messaggio – o codice – viene inviato mediante due tipi di tecniche di commutazione:
- “di circuito”, caratterizzata da un collegamento stabile tra due utenti, per tutta la durata della comunicazione;
- “di pacchetto”, quando più utenti inviano simultaneamente informazioni attraverso la rete, servendosi dello stesso canale di comunicazione.
Le reti informatiche in genere, vengono catalogate in base alla loro estensione e funzionalità.
La rete “LAN”
Acronimo inglese di “Local Area Network”, la LAN è una rete che si crea all’interno di aree circoscritte in cui le informazioni viaggiano attraverso un semplice cavo Ethernet o mediante canali bluetooth o wifi quali un’abitazione, oppure un ufficio, una fabbrica, o una scuola.
Con questo tipo di rete, in genere, si condividono risorse hardware come stampanti o scanner, atri dispositivi IoT, oppure risorse software, dove possono essere gestiti documenti e file di qualsiasi tipo.
La rete “MAN”
Acronimo inglese di “Metropolitan Area Network”, la MAN è un tipo di rete informatica che entra in gioco quando le informazioni e i dati devono raggiungere distanze più grandi ed essere condivise all’interno di una città.
In questo caso, ci si appoggia alle reti di dominio pubblico come, in genere, la rete telefonica, la quale è in grado di raggiungere la quasi totalità degli edifici e di collegare diverse reti locali, in cavo, in fibra, o mediante wifi.
La rete “WAN”
Acronimo inglese di “Wide Area Network”, la WAN è una tipologia di rete molto estesa, che arriva ad abbracciare città, nazioni e interi continenti, connettendo insieme ovviamente, sia le reti LAN che MAN.
Le Wide Area Network sono possedute da una determinata organizzazione o azienda e vengono gestite privatamente o affittate, inoltre i fornitori di servizi Internet (ISP, Internet Service Provider) utilizzano le WAN per allacciare le reti delle aziende ed i clienti finali ad Internet.
Con la complessità moderna inerente le evoluzioni delle infrastrutture, si possono anche definire reti le seguenti:
Le reti “PAN” o “WPAN”
Acronimo inglese di “Personal Area Network” o “Wireless Personal Area Network”, sono piccole reti “ad och” che usufruiscono di connessioni “USB” o bluetooth.
Una Wireless Personal Area Network che funziona tramite bluetooth prende il nome di “piconet”.
Le connessioni PAN e WPAN si estendono normalmente per pochi metri e non sono quindi adatte a collegare dispositivi in stanze diverse o in altri edifici.
La rete “GAN”
Acronimo inglese di “Globe Area Network”, la rete (GAN) dovrebbe identificare la rete globale delle connessioni di tutti i “nodi”, Tuttavia una rete come “Internet” non è l’unica nel suo genere.
Vi sono compagnie che gestiscono delle reti chiuse, che comprendono diverse WAN e così riescono a mettere in contatto i propri computer a livello mondiale IN MANIERA ESCLUSIVA.
Le GAN utilizzano le infrastrutture a fibra ottica delle WAN e le congiungono attraverso cavi sottomarini internazionali o trasmissioni satellitari.
Le reti virtuali “VPN”
Acronimo inglese “Virtual Private Network” la rete VPN è una rete di comunicazione virtuale che utilizza l’infrastruttura di una rete fisica, per connettere dei sistemi in maniera criptografata.
Solitamente si tratta di una rete che utilizza dei “tunnel Internet” come mezzo di trasporto, così da collegare i computer a livello mondiale ed essere disponibile gratuitamente, contrariamente alle MAN o alle WAN che sono gestite privatamente, il trasferimento dati avviene tramite un sistema di codifica / decodifica virtuale, il quale serve a stabilire una connessione tra un client VPN ed un server VPN.
Lo scopo d’utilizzo delle VPN è solitamente la connessione di diverse LAN su Internet, o quello di rendere possibile l’accesso remoto ad una rete o di un singolo computer tramite connessione pubblica.
Un indirizzo IP costituisce dunque, la base per la comunicazione delle informazioni dal mittente al ricevente.
Nella accezione più comune, la rete è composta dai nodi, o se vogliamo da “host”, che possono essere sia servizi software o anche apparecchiature identificate proprio da un indirizzo IP, che, come sopra descritto, ha due caratteristiche principali: essere pubblico o essere privato e due caratteristiche secondarie, essere statico o essere dinamico.
N.B. Il termine “host” deriva dalla radice latina, hospitem, dove significa “padrone di casa”, “oste” (il padrone del bar!), e si è evoluto nel contesto informatico per indicare un dispositivo che fornisce risorse o servizi (come un server web) ad altri dispositivi o utenti (“ospiti” o “client”).
Pertanto, l’indirizzo IP pubblico è un indirizzo visibile e raggiungibile da tutti gli host della rete Internet, mentre quello privato viene usato per identificare in modo univoco un dispositivo appartenente a una rete locale.
Gli indirizzi dinamici sono i più utilizzati e vengono impiegati per la normale navigazione online, questi vengono solitamente forniti da un Internet Service Provider che assegna un indirizzo IP casuale temporaneo che viene modificato con cadenza prestabilita.
Gli IP dinamici garantiscono una maggiore protezione della privacy degli utenti consentendo una navigazione più anonima.
Un indirizzo IP statico, ovviamente, rimane invariato, tuttavia il proprietario può richiederne la modifica, se pubblico.
Gli IP statici sono solitamente utilizzati nelle LAN o PAN, (reti private) per comunicare, con una stampante o un altro computer della sotto-rete locale.
L’indirizzo IP si compone a sua volta, di due parti: la prima è un indicatore di rete “Net_ID” e la seconda è l’indicatore di host “Host_ID”: la parte Net_ID è assegnata dall’ICANN (Internet Corporation for Assigned Names and Numbers), che a sua volta delega organizzazioni regionali (Europa, Asia, ecc) che a loro volta delegano altre organizzazioni (per l’Italia l’organizzazione preposta è il GARR).
L’ ICANN ha il compito di assegnare gli indirizzi IP ed ha l’incarico di identificatore di gestire il sistema dei nomi di dominio di primo livello (Top-Level Domain) generico (gTLD), del codice internazionale (ccTLD) e dei sistemi di root server della GAN.
Questo indirizzo è un codice di 48 bit (6 byte) assegnato in modo univoco dal produttore ad ogni scheda di rete ethernet o wireless prodotta al mondo.
Per rendere maggiormente user-friendly la tecnologia IP sono stati implementati alcuni servizi di risoluzione dei nomi, cioè che associano un nome leggibile ad un determinato indirizzo, ovvero un sistema denominato “DNS”, acronimo inglese di “Domain Name System” che è un servizio di directory utilizzato per la risoluzione dei “nomi dei server” fornendo la corrispondenza tra indirizzi logici e testuali “URL”, acronimo inglese di “Uniform Resource Locator” e indirizzi IP.
La peculiarità del DNS è quella di consentire, ad esempio ad un sito web, di essere ospitato su più server, ognuno con il proprio indirizzo IP, con una conseguente divisione del carico di lavoro.
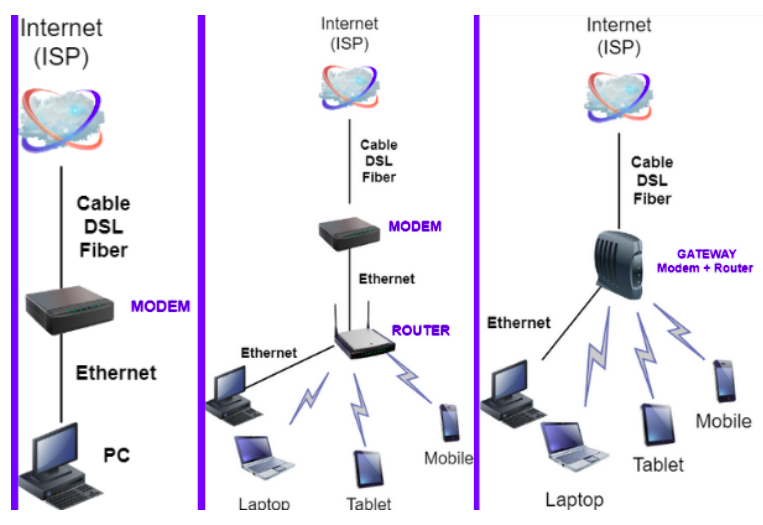
Per concludere, ogni nodo di Internet ha quindi assegnato un indirizzo IP univoco, all’interno di una LAN, gli indirizzi IP possono essere assegnati manualmente dall’amministratore di rete (IP statico) oppure, come di norma accade, l’assegnazione avviene in maniera automatizzata attraverso un server DHCP, acronimo inglese di “Dynamic Host Configuration Protocol”, tipicamente installato su un “Router”, preposto al rilascio di indirizzi, che utilizza una “maschera di sotto rete” per identificare i componenti di una rete privata, che a loro volta, attraverso un “Gateway” che utilizzando il sistema DNS si possono connettere sia in funzione di client che di server.
Solitamente la funzione di gateway viene svolta dallo stesso router.
Il gateway è quindi un dispositivo o il software che effettua una traduzione di protocollo tra due reti, mentre il router è un dispositivo responsabile dell’instradamento di pacchetti di dati attraverso una rete.
Il modello di comunicazione standardizzato a livello internazionale è denominato “OSI”, acronimo di “Open Systems Interconnection”, dall’International Organization for Standardization (ISO).
In figura viene rappresentata la funzionalità specifica dei componenti che sono adibiti alla gestione hardware e software delle connessioni internet per una piccola rete locale.
Subnet mask
Una subnet mask è un numero a 32 bit che, nell’ambito delle reti TCP/IP, serve a dividere un indirizzo IP in due parti: l’indirizzo della rete (network ID) e l’indirizzo del dispositivo specifico (host ID).
Questo permette ai dispositivi di capire se un altro host si trova sulla stessa rete locale (e quindi comunicare direttamente) o su una rete remota, inoltrando i dati al gateway.
Funziona tramite un’operazione logica AND, identificando la parte di rete con i bit a ‘1‘ e la parte host con i bit a ‘0‘.
A cosa serve:
- Identificazione Rete/Host: distingue quale porzione dell’IP identifica la rete e quale il singolo dispositivo.
- Efficienza di Rete: suddivide una grande rete in sottoreti più piccole (subnetting) per ridurre traffico, migliorare la sicurezza e la gestione.
- Routing: I router usano la subnet mask per determinare il percorso corretto dei pacchetti di dati.
Come funziona (in breve):
Struttura: È un numero di 32 bit, scritto come quattro ottetti (es. 255.255.255.0).
- Bit a ‘1’: corrispondono alla parte di rete dell’indirizzo IP.
- Bit a ‘0’: corrispondono alla parte host dell’indirizzo IP.
Operazione logica AND: il computer fa un’operazione AND tra il proprio IP e la subnet mask per trovare l’indirizzo di rete, e un’operazione simile sull’IP di destinazione per confrontare le reti.
Esempio: Con una subnet mask di 255.255.255.0, i primi tre ottetti (255) indicano la rete, mentre l’ultimo ottetto (0) identifica gli host.
Se un altro IP ha gli stessi primi tre ottetti, è sulla stessa rete.
Le porte
Se il mittente lancia un messaggio diretto ad un terminale, deve aver elaborato l’indirizzo IP completo, utilizzando anche la maschera che gli permette di arrivare davanti alla porta di casa o di stanza, ma a quel punto, dovrà bussare per entrare: un indirizzo IP o un protocollo Internet viene utilizzato per fornire dati attraverso le connessioni di rete.
Questo indirizzo è costituito da una stringa di numeri che fungono da identificatore univoco.
I numeri di porta sono un numero intero senza segno, a 16 bit, aggiunto a questa stringa, separato da due punti, ad esempio 10.100.100.100: 5000.
Questo numero aggiunto è chiamato “numero di porta” e viene utilizzato per dirigere il traffico Internet quando arriva a un server o assegnato in maniera autonoma ad un client, dal sistema operativo.
Il protocollo TCP (Transmission Control Protocol) e il protocollo UDP (User Datagram Protocol) vengono utilizzati per instradare un pacchetto di dati al processo corretto.
Esistono numerosi numeri di porta e sono una parte fondamentale del funzionamento delle reti Internet.
I numeri di porta internet sono identificatori numerici (da 0 a 65535) che indirizzano i pacchetti dati verso applicazioni specifiche su un computer, dividendo il traffico tra servizi come Web (HTTP 80, HTTPS 443), E-mail (SMTP 25, POP3 110, IMAP 143), File (FTP 21) e Risoluzione Nomi (DNS 53), con le porte 0-1023 riservate ai servizi standard (Well-Known Ports) e le altre per usi dinamici o registrati.
In particolare le porte comuni associate a servizi sono:
- Porte Ben Note (0-1023): Servizi standardizzati.
- 21 (TCP): FTP (File Transfer Protocol) per trasferimento file.
- 23 (TCP): Telnet per accesso remoto (meno sicuro).
- 25 (TCP): SMTP (Simple Mail Transfer Protocol) per invio email.
- 53 (TCP/UDP): DNS (Domain Name System) per tradurre nomi in IP.
- 80 (TCP): HTTP (HyperText Transfer Protocol) per navigazione web.
- 110 (TCP): POP3 (Post Office Protocol) per ricezione email.
- 143 (TCP): IMAP (Internet Message Access Protocol) per gestione email.
- 443 (TCP): HTTPS (HTTP Secure) per navigazione web sicura (crittografata).
- Porte Registrate (1024-49151): per applicazioni specifiche (es. RDP 3389, NTP 123).
- Porte Dinamiche/Private (49152-65535): usate per connessioni temporanee.
Le porte sono fondamentali perché un singolo indirizzo IP può gestire molti servizi contemporaneamente; il numero di porta indica al sistema operativo quale applicazione (es. browser web, client email, server DNS) deve ricevere i dati in arrivo, separando le comunicazioni.
intranet:
Le reti intranet sono reti informatiche private e sicure, utilizzate esclusivamente dai membri di un’organizzazione (come dipendenti e collaboratori) per condividere informazioni, documenti e risorse, migliorare la comunicazione interna e organizzare le attività. Sfruttano le stesse tecnologie di Internet, come TCP/IP, ma sono protette da un accesso non autorizzato tramite firewall e password.
Funzionalità principali:
- Condivisione di informazioni: Permettono la condivisione di documenti, procedure aziendali e altri file in modo centralizzato.
- Comunicazione: Includono strumenti come forum, bacheche e messaggistica istantanea per favorire la collaborazione tra i dipendenti.
- Accesso centralizzato: Funzionano come un unico punto di accesso per le risorse aziendali, ottimizzando il tempo e semplificando le attività.
- Gestione e sicurezza: Offrono un ambiente controllato per gestire le risorse interne e proteggere i dati riservati da accessi esterni.
- Formazione: Possono essere usate per distribuire materiali didattici, corsi online e aggiornamenti aziendali.
Differenza con Internet:
Internet: è una rete pubblica e globale, accessibile a chiunque.
Intranet: è una rete privata e locale, accessibile solo a un gruppo selezionato di persone all’interno di un’organizzazione.
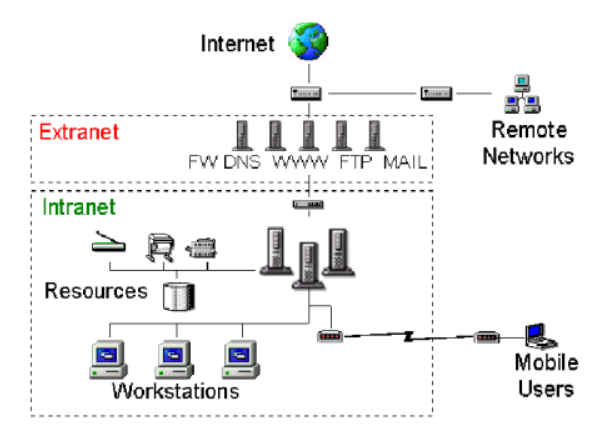
L’Extranet rappresenta un’estensione controllata dell’Intranet, accessibile a utenti esterni selezionati, come fornitori, clienti o partner commerciali e funziona come un ponte tra la rete interna e il mondo esterno, consentendo una condivisione limitata di informazioni e risorse.
Dispositivi di rete
I dispositivi di rete sono apparecchiature che gestiscono il traffico dei dati, come router, modem e switch, gestiscono il traffico, inviano e ricevono i messaggi all’interno della rete.
modem:
È quel dispositivo che si collega alla linea del provider (es. telefonica o fibra) per stabilire una connessione con Internet.
Router:
È quel dispositivo che si occupa di distribuire questa connessione a più dispositivi all’interno della rete locale.
I router wireless dispongono di antenne per trasmettere il segnale Wi-Fi, collegando dispositivi senza fili.
Modem router:
Un’unica apparecchiatura che combina entrambe le funzioni, fungendo sia da modem che da router.
access point:
Questo è un dispositivo di rete che collega apparecchiature wireless, come smartphone e laptop, a una rete cablata locale (LAN) tramite Wi-Fi.
È diverso da un router, anche se le funzioni sono spesso integrate nei moderni router Wi-Fi; un AP agisce come un ponte wireless, estendendo la portata del Wi-Fi in un’area dove il segnale è debole o inesistente.
L’access point si collega tramite un cavo Ethernet a un router esistente, creando una rete wireless separata o estendendo quella esistente.
Una volta collegato, l’AP crea un punto di accesso Wi-Fi a cui i dispositivi possono connettersi.
I dispositivi wireless comunicano con l’access point, che a sua volta inoltra il traffico di rete al router principale e quindi a Internet.
Le differenze tra un router ed un AP potrebbe essere sintetizzata come segue: un router gestisce l’intera rete, assegna indirizzi IP e fornisce accesso a Internet, mentre un AP si occupa specificamente di creare e gestire la connessione wireless.
Molti dispositivi domestici moderni combinano le funzioni di router, modem e access point in un unico apparecchio chiamato modem-router.
Funzionalità di estensione: un access point è ideale per estendere la copertura Wi-Fi, specialmente in case grandi o uffici dove il segnale del router principale non arriva ovunque.
Connessione fisica: a differenza di un range extender o ripetitore Wi-Fi che riceve il segnale via cavo (wireless), un access point si collega tramite cavo Ethernet al router, garantendo una connessione più stabile e veloce.
Accesso: Un access point non gestisce l’assegnazione di indirizzi IP o il firewall, compiti che rimangono a carico del router.
Hub:
Un hub è un dispositivo semplice che ripete i dati a tutte le porte.
Switch:
Uno switch è un dispositivo di rete che collega più dispositivi (come computer, stampanti, server) in una rete locale (LAN), permettendo loro di comunicare tra loro in modo efficiente inoltrando i pacchetti di dati direttamente al destinatario, invece di inviarli a tutti, a differenza degli hub.
Gateway:
Un gateway (o “cancello”) in informatica è un dispositivo hardware/software che collega due reti diverse, traducendo i protocolli per permettere la comunicazione, come il tuo router che collega la rete locale a Internet (gateway predefinito). Esistono molti tipi, dai gateway di pagamento per le transazioni online ai gateway IoT per i sensori, fino ai gateway VPN per l’accesso remoto, fungendo da punto d’ingresso/uscita e traducendo formati diversi per garantire interoperabilità e sicurezza tra sistemi differenti.
Dispositivi IoT:
I dispositivi IoT (Internet of Things) sono oggetti fisici dotati di sensori, software e connettività di rete che permettono loro di raccogliere, scambiare e trasmettere dati via Internet.
Esempi comuni includono smartphone, smartwatch, assistenti vocali come Alexa e Google Home, elettrodomestici intelligenti (es. frigoriferi), sistemi di sicurezza domestica, e componenti industriali, questi dispositivi consentono di automatizzare processi, migliorare l’efficienza e fornire comodità nella vita quotidiana e in ambito professionale.
Client:
È un dispositivo (o un software) che richiede servizi e dati da un server, come computer, smartphone, tablet, smart TV, o anche browser web e app di posta elettronica, che sono programmi che si connettono a server per ottenere informazioni, rendendo il client la parte che “chiede” e utilizza le risorse di una rete.
Server:
È un dispositivo, spesso un computer potente o un sistema informatico, progettato per fornire servizi, risorse e dati (come file, applicazioni, email) a altri dispositivi o programmi, chiamati “client”, attraverso una rete (come Internet).
Può essere un’entità hardware (il computer fisico) o software (il programma che gestisce le richieste), ma comunemente il termine si riferisce a una macchina fisica dedicata, in grado di funzionare 24/7 per gestire le richieste di molti utenti contemporaneamente, come un sito web o un servizio di posta elettronica.
Terminali:
Dispositivi con cui gli utenti interagiscono, e possono essere classificati in base a varie caratteristiche:
- Computer (Desktop/Laptop): dispositivi completi per ogni esigenza.
- Dispositivi Mobili: smartphone e tablet che usano connessioni cellulari o Wi-Fi.
- Dispositivi IoT: termostati, telecamere, assistenti vocali, auto connesse, ecc..
- Stampanti/Scanner: dispositivi di rete per la stampa e la scansione ecc.
questi dispositivi possono essere connessi alla rete usufruendo di tecnologie diverse:
- Rete Cablata: ADSL, Fibra Ottica (FTTH, FTTC).
- Wireless:
- FWA (Fixed Wireless Access): Connessione fissa tramite onde radio (antenne).
- Satellitare: Per aree remote, tramite parabola.
- Mobile (4G/5G): Tramite SIM, router, AP (saponette ecc.).
La stima dei terminali internet globali è enorme e in crescita, comprendendo miliardi di utenti connessi (oltre 5,5 miliardi nel 2025), ma soprattutto dispositivi che superano i 14 miliardi, con proiezioni di oltre 30 miliardi entro il 2025 per l’IoT, più smartphone, PC e altri oggetti di rete.

protocolli di rete
I protocolli di rete sono insiemi di “regole grammaticali” che definiscono come i dispositivi comunicano e scambiano dati su una rete.
Funzionano come un “linguaggio comune” che permette a sistemi diversi di dialogare tra loro in modo efficiente e accurato, specificando come impacchettare, inviare e ricevere i dati.
Questi “protocolli”, garantiscono che i sistemi fisici, i dispositivi hardware di rete e i “terminali”, o utenti finali, riescano a comunicare tra loro, nonostante le loro diversità strutturali, l’IP (Internet Protocol) ad esempio ha lo scopo di identificare e indirizzare i pacchetti di dati.
Esempi di protocolli comuni
- IP (Internet Protocol): sistema di instradardamento per i pacchetti di dati verso la destinazione corretta attraverso l’indirizzamento.
- TCP (Transmission Control Protocol): Si occupa di stabilire una connessione affidabile e di garantire che tutti i pacchetti arrivino a destinazione correttamente, in un ordine preciso.
- UDP (User Datagram Protocol): Un protocollo più veloce e meno “costoso” del TCP, che non garantisce la consegna nell’ordine corretto, utilizzato per applicazioni che non richiedono alta affidabilità (come lo streaming video).
- HTTP(s) (HyperText Transfer Protocol): Protocollo utilizzato per il trasferimento di pagine web.
- ICMP (Internet Control Message Protocol): Usato per inviare messaggi di errore e di controllo, come nel comando ping per verificare la raggiungibilità di un host.
- SMTP, POP3, IMAP: protocolli specifici per l’invio e la ricezione di email.
Formati di dati e applicativi
- JSON (JavaScript Object Notation): un formato leggero e leggibile, molto usato per lo scambio di dati tra applicazioni web e mobile (API).
- XML (Extensible Markup Language): un formato strutturato per definire e trasmettere dati complessi, usato in vari settori.
- HTML (HyperText Markup Language): non è un linguaggio di programmazione, ma il linguaggio di marcatura per strutturare il contenuto delle pagine web, che viene poi interpretato dai browser.
In sintesi, mentre il TCP/IP è il fondamento tecnico, HTTP/HTTPS e formati come JSON/XML sono i “linguaggi” specifici che gli utenti e le applicazioni utilizzano quotidianamente per interagire e scambiare contenuti sul web.
A quelli sopra descritti, vanno aggiunti, per sistemi che richiedono velocità estrema e risparmio di banda (come i microservizi o lo streaming di dati), i formati non leggibili direttamente dall’uomo:
- Protocol Buffers (Protobuf): sviluppato da Google, è un formato binario compatto ideale per comunicazioni ad alte prestazioni tra server.
- Avro e Thrift: utilizzati principalmente in ecosistemi di Big Data e sistemi distribuiti per la loro efficienza nel gestire schemi di dati evolutivi.
In qualsiasi caso, in questi tempi moderni, dove l’automazione la fa da padrona su tutto, si fa riferimento al metodo per scambiare documenti e dati denominato EDI, acronimo di (Electronic Data Interchange), che utilizzando protocolli sicuri come AS2/AS4, i sistemi informatici (gestionali, ERP) si parlano direttamente scambiando dati strutturati, senza intervento umano.
Tutta questa lunga introduzione, per portare il lettore a concepire un esempio pratico.
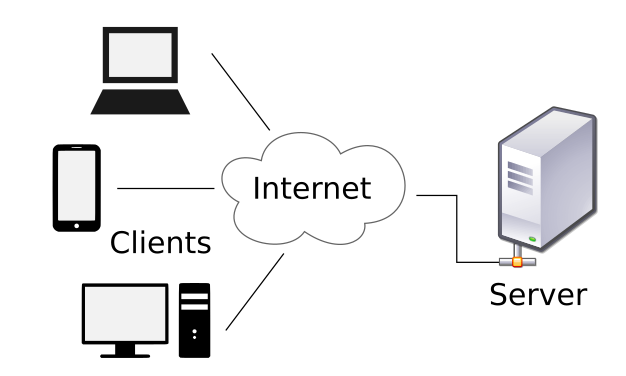
Client e server
In sintesi, è un sistema di dispositivi utilizzanti un dialogo strutturato: il client chiede, il server risponde, e i protocolli assicurano che entrambi parlino la stessa “lingua” attraverso il percorso di rete che condividono.
Il client invia una richiesta al server, ad esempio utilizzando un metodo di chiamata GET o POST, indirizzandola all’IP e alla porta corretti, usando un protocollo (es. HTTP(s)).
Metodo GET
- Scopo: richiedere (recuperare) dati da una risorsa specificata.
- Invio Dati: parametri aggiunti direttamente all’URL (es.
?param1=valore¶m2=valore). - Visibilità: i dati sono visibili nella barra degli indirizzi del browser.
- Limitazioni: quantità di dati limitata (circa 1500 caratteri).
- Uso: ricerche, filtri, navigazione, segnalibri (bookmarking).
- Sicurezza: meno sicuro per dati sensibili (es. password) perché i dati sono in chiaro nell’URL
Metodo POST
- Scopo: inviare dati a un server per creare o aggiornare una risorsa.
- Invio Dati: dati inviati nel corpo della richiesta HTTP, non nell’URL.
- Visibilità: dati nascosti nel corpo della richiesta.
- Limitazioni: nessun limite pratico alla dimensione dei dati.
- Uso: form di login, registrazione, invio di commenti, caricamento di file.
- Sicurezza: più sicuro per dati sensibili se usato con HTTPS, poiché i dati non sono esposti nell’URL.
Un caso pratico
Si supponga di voler monitorare due parametri inerenti grandezze fisiche ambientali, ad esempio temperatura ed umidità e di volerle inviare ad un server per eventuali elaborazioni o esposizioni su una pagina web: servono due dispositivi, un client, che può essere costituito da un Raspberry Pi Pico w, che acquisisce i dati da un apposito sensore, ed ad esempio il DHT11, ed un server, ad esempio un Raspberry Pi 4B, dotato di un touch screen per la visualizzazione dei dati acquisiti dal client, su una pagina web, riportando eventualmente anche i dati elaborati per il settaggio di allarmi.
Il server, potrebbe a sua volta trasferire i dati ad un altro dispositivo client, per controllare degli azionamenti, in funzione a delle elaborazioni dei valori elaborati.
Il Client.
In questo caso si è pensato ad un dispositivo adatto ad effettuare una connessione WIFI, che si prestasse anche ad essere dotato di un sensore di umidità e temperatura, come il Raspberry Pi Pico w:

che è un microcontrollore, progettato specificamente per progetti di elettronica, IoT e physical computing, a differenza dei tradizionali Raspberry Pi (come il 4 o 5) che sono computer a scheda singola con sistema operativo, la versione “W” aggiunge la connettività Wi-Fi, rendendolo ideale per applicazioni che richiedono comunicazione wireless, programmabile in C/C++ e MicroPython, questo microcontrollore è basato sul chip RP2040 di Raspberry PI.
Il sensore di temperatura ed umidità.
Il DHT11 è un sensore di umidità relativa e temperatura che emette un segnale digitale.
Utilizza un sensore di umidità capacitivo e un termistore per misurare l’umidità e la temperatura dell’aria circostante.

Il campo di misura della temperatura del DHT11 va da 0°C a +50°C, con una precisione di ±2°C.
Il campo di misura dell’umidità va dal 20% al 90%, con una precisione di ±5%.
La frequenza di campionamento del sensore è di 1Hz, il che significa che i dati del sensore possono essere letti solo una volta al secondo.
Principio di funzionamento del componente:
Il componente di rilevamento dell’umidità viene utilizzato per misurare l’umidità, e ha due elettrodi con substrato che trattiene l’umidità (di solito sale o polimero plastico conduttivo) inserito tra gli elettrodi.
Gli ioni vengono rilasciati dal substrato mentre il vapore acqueo viene assorbito da quest’ultimo, il che a sua volta aumenta la conducibilità tra gli elettrodi.
La variazione della resistenza tra i due elettrodi è proporzionale all’umidità relativa. L’umidità relativa più alta diminuisce la resistenza tra gli elettrodi, mentre l’umidità relativa più bassa aumenta la resistenza tra gli elettrodi.
La parte di rilevamento della temperatura del sensore DHT11 è costituita da un termistore NTC.
Un termistore è una resistenza termica, una resistenza che cambia la sua resistenza con la temperatura.
Tecnicamente, tutte le resistenze sono termistori, la loro resistenza cambia leggermente con la temperatura, ma la variazione è di solito piccola e difficile da misurare. I termistori sono realizzati in modo che la resistenza cambi drasticamente con la temperatura.
La variazione può essere di 100Ω o più per grado di temperatura.
Il termine NTC significa Coefficiente di Temperatura Negativo, il che significa che la resistenza diminuisce con l’aumento della temperatura.
In output, c’è un piccolo PCB con un circuito integrato configurato a 8 bit (SOIC14).
Il circuito integrato misura ed elabora il segnale analogico con i coefficienti di calibrazione memorizzati, effettua la conversione da analogico a digitale ed emette un segnale digitale con i dati che contiene le informazioni per la temperatura e l’umidità.
PINOUT:
Il Pin di alimentazione (+): fornisce l’alimentazione al sensore.
Anche se la tensione di alimentazione può variare tra 3,3V e 5V, si raccomanda un’alimentazione a 5V.
In caso di alimentazione а 5V, un cavo che collega il sensore al microcontrollore può essere lungo fino a 20 metri.
Tuttavia, con una tensione di alimentazione di 3,3V, la lunghezza del cavo non deve essere superiore a un metro, altrimenti la caduta di tensione di linea porterà ad errori di misura.
Il Pin OUT (DATA): è il pin dati, e viene utilizzato per la comunicazione tra il sensore e il microcontrollore.
Il Pin GND (-): è pin “di terra” e deve essere collegato “alla terra comune”, o 0V.
Per il Raspberry Pi Pico w, il pinout viene riportato dalla seguente immagine:
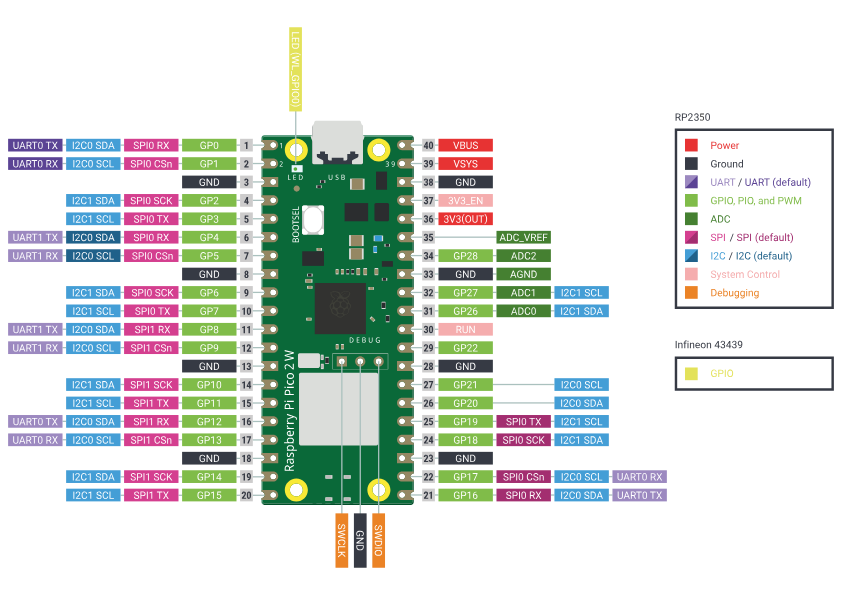
La connessione tra il Raspberry Pi Pico – W e il DHT11, potrà essere effettuata ad esempio, utilizzando i Pin del Pico-W N. 26 (3.3V Out), Il Pin 38 (GND), o un altro con la stessa funzione, e il Pin N.1 (GP0).
Il software per il Client
MicroPython è un’implementazione snella ed efficiente del linguaggio di programmazione Python 3 che include un piccolo sottoinsieme della libreria standard Python ed è ottimizzato per l’esecuzione su microcontrollori e in ambienti limitati.
Il pyboard MicroPython è un circuito elettronico compatto che esegue MicroPython sul bare metal, offrendo un sistema operativo Python di basso livello che può essere utilizzato per controllare tutti i tipi di progetti elettronici.
MicroPython è ricco di funzionalità avanzate come un prompt interattivo, numeri interi di precisione arbitraria, chiusure, comprensione di elenchi, generatori, gestione delle eccezioni e altro ancora.
Eppure è sufficientemente compatto da poter essere installato ed eseguito in soli 256k di spazio di codice e 16k di RAM.
MicroPython mira a essere il più compatibile possibile con il normale Python per consentire di trasferire facilmente il codice dal desktop a un microcontrollore o un sistema integrato.
MicroPython, in sintesi, è un compilatore runtime Python completo che funziona a basso livello, riuscendo ad ottenere un prompt interattivo (REPL) per eseguire immediatamente i comandi, insieme alla possibilità di eseguire e importare script dal filesystem integrato.
REPL dispone di cronologia, completamento tramite tabulazione, rientro automatico e modalità incolla per un’ottima esperienza utente, molto simile al Python.
Oltre a implementare una selezione di librerie Python principali, MicroPython include moduli come “machine”, ideato proprio per l’accesso all’hardware di basso livello.
Listato del codice in Micropython
# versione B_01
# ok lettura sensore DHT11
# ok connessione
# ok trasmissione dati al server
import network
import urequests
import time
from machine import Pin
import dht
# --- CONFIGURATION ---
SSID = 'xxxxxx'
PASSWORD = 'yyyyyy'
SERVER_URL = 'http://10.100.100.100:5000/upload' # Replace with RPi server IP address
DHT_PIN = 0 # GPIO pin connected to DHT11
# --- SETUP ---
wlan = network.WLAN(network.STA_IF)
sensor = dht.DHT11(Pin(DHT_PIN))
def connect_wifi():
"""Connect to the WiFi network."""
wlan.active(True)
wlan.connect(SSID, PASSWORD)
print('Connecting to WiFi...')
max_wait = 10
while max_wait > 0:
if wlan.status() < 0 or wlan.status() >= 3:
break
max_wait -= 1
print('waiting for connection...')
time.sleep(1)
if wlan.status() != 3:
raise RuntimeError('Network connection failed')
else:
print('Connected')
status = wlan.ifconfig()
print('IP = ' + status[0])
def send_data(temp, hum):
"""Send temperature and humidity to the server."""
data = {'temperature': temp, 'humidity': hum}
try:
response = urequests.post(SERVER_URL, json=data)
print('Data sent:', response.text)
response.close()
except Exception as e:
print('Failed to send data:', e)
# --- MAIN LOOP ---
try:
connect_wifi()
while True:
try:
print('Reading sensor...')
sensor.measure()
temp = sensor.temperature()
hum = sensor.humidity()
print(f'Temperature: {temp} C, Humidity: {hum}%')
send_data(temp, hum)
except OSError as e:
print('Failed to read sensor.')
# Wait for 300 seconds (5 minutes)
print('Waiting 300 seconds...')
time.sleep(300)
except Exception as e:
print('An error occurred:', e)Il Server
Il sever potrebbe essere costituito da un qualsiasi PC o dispositivo di rete, ma per questo progetto didattico, ho scelto un SBC (single-board computer) della stessa famiglia del Client, anche perché economicamente alla portata di tutti coloro i quali volgono sperimentare applicazioni di elettronica, o per laboratori didattici di ogni ordine e grado.
La storia del Raspberry Pi inizia nel 2006 con l’idea di Eben Upton e la Raspberry Pi Foundation (UK) di creare un microcomputer a basso costo per insegnare la programmazione agli studenti, ispirandosi ai computer Amiga e BBC Micro.
Lanciato nel 2012, è a tutti gli effetti, un computer a scheda singola (SBC) reso famoso per il suo prezzo accessibile, il design compatto e la versatilità, trasformandosi da strumento educativo in un fenomeno globale per hobbisti, maker ed anche per applicazioni industriali.
Dalle origini al successo (2006-2012)
- Nascita dell’idea (2006): Eben Upton e un gruppo di accademici e appassionati iniziano a concepire un piccolo computer economico per stimolare l’interesse verso l’informatica e la programmazione.
- Prototipi: I primi prototipi si basavano su microcontrollori Atmel, ma l’obiettivo era creare un dispositivo più potente e versatile.
- Creazione della Fondazione: Nasce la Raspberry Pi Foundation, un’organizzazione no-profit con sede a Cambridge, per promuovere il progetto.
- Lancio (2012): Il primo modello, il Raspberry Pi 1 Model B, viene rilasciato a febbraio 2012, con un processore single-core, 256/512 MB di RAM e uscite HDMI/USB.
Evoluzione e espansione (2012-Oggi):
- Successo inaspettato: Il dispositivo diventa molto più popolare del previsto, venendo adottato anche al di fuori del contesto educativo per progetti di robotica, automazione domestica e hobbistica.
- Modelli e potenziamento: Vengono rilasciati numerosi modelli, con CPU più potenti (quad-core), più RAM (fino a 8GB) e funzionalità avanzate, mantenendo sempre un prezzo competitivo.
- Software: Nascono sistemi operativi dedicati come Raspberry Pi OS (ex Raspbian), ottimizzati per la piattaforma.
- Applicazioni: Dall’educazione si espande all’IoT, al monitoring industriale e alla prototipazione rapida, diventando uno strumento indispensabile per sviluppatori e maker.
Il ruolo di Raspberry Pi:
- Democratizzazione dell’informatica: Ha abbassato le barriere d’ingresso, rendendo l’apprendimento della programmazione e dell’elettronica accessibile a tutti.
- Flessibilità: Con porte standard (USB, HDMI, Ethernet, GPIO), permette di connettere facilmente periferiche e sensori, alimentando la creatività.
- Forte comunità: Una vasta comunità di utenti supporta e sviluppa continuamente nuovi progetti e soluzioni.
PINOUT Raspebrry PI 4B

Il sistema operativo
Raspberry Pi OS è un sistema operativo gratuito basato su Debian ottimizzato per l’hardware Raspberry Pi.
Il sistema operativo Raspberry Pi supporta oltre 35.000 pacchetti Debian.
Poiché il sistema operativo Raspberry Pi deriva da Debian, segue una versione scaglionata del ciclo di rilascio di Debian e dunque, le nuove distribuzioni, avvengono all’incirca ogni 2 anni.
Debian è Software Libero: Debian è realizzato con Software Libero e open source e rimarrà sempre Libero al 100%.
Questo significa: Libertà per chiunque di utilizzarlo, modificarlo e distribuirlo.
Debian è anche gratuito.
La storia di Debian:
La storia di Debian inizia nell’agosto 1993 con Ian Murdock, che creò una distribuzione GNU/Linux libera e aperta, basata sul kernel Linux, con l’obiettivo di essere mantenuta con cura dalla comunità del software libero.
Il nome si deve alla composizione dei due nomi Debra e Ian Deb+Ian (debra è la compagna di Ian). Dopo un inizio modesto, crebbe fino a diventare una grande comunità, pubblicò il suo Manifesto nel ’94, rilasciò la prima versione stabile (1.1 “Buzz”) nel ’96, e si distinse per il suo sistema di gestione pacchetti (APT) e la sua filosofia di sviluppo trasparente e collaborativo.
Nascita e fondazione:
- 1993: Ian Murdock lancia il progetto per creare una distribuzione Linux che fosse completamente aperta, in linea con lo spirito GNU.
- Manifesto Debian: Pubblicato nel gennaio 1994, definisce i principi fondamentali del progetto.
Sviluppo e crescita:
- Prima versione stabile (1.1 “Buzz”): Rilasciata nel giugno 1996, segnò l’inizio di una tradizione di nomi in codice tratti da personaggi di Toy Story.
- Successione: Bruce Perens successe a Ian Murdock come leader del progetto e introdusse la convenzione dei nomi in codice.
- Contratto Sociale: Approvato nel 1997, definisce gli impegni di Debian verso il software libero.
- Innovazione: Introdotto il sistema di gestione pacchetti APT (Advanced Package Tool) e il formato di pacchetto
.deb, rendendo gli aggiornamenti e la gestione del software molto più semplici e stabili. - Espansione: Diventò una delle più importanti distribuzioni Linux, diventando la base per molte altre (come Ubuntu) e supportando numerose architetture hardware.
Caratteristiche distintive:
- Trasparenza e Comunità: Una delle poche grandi distribuzioni non commerciali con un processo di sviluppo aperto e ben documentato.
- Stabilità: Famosa per la sua stabilità, ottenuta grazie a un’attenta gestione delle dipendenze tra i pacchetti.
- Filosofia: Dedizione al software libero, con un forte impegno verso principi etici e libertà!
A tal proposito, consiglio la lettura di un mio libro che è pubblicato su piattaforma Amazon:

Di cui riporto un breve stralcio della prefazione scritta da Cheshire cat AI. (https://cheshirecat.ai/):
…”In un mondo sempre più connesso e interconnesso, la filosofia Open Source si erge come una luce guida per coloro che cercano la condivisione del sapere e della creatività. Con le sue radici profonde nella cultura del software libero, l’Open Source abbraccia l’idea che il progresso non debba essere ostacolato da restrizioni o segreti, ma piuttosto incoraggiato dalla collaborazione e dalla trasparenza.
La filosofia Open Source celebra l’idea che il software, le conoscenze e le idee siano accessibili a tutti. Attraverso la condivisione e la collaborazione, le menti creative possono dare vita a progetti straordinari, spingendo i confini dell’innovazione e aprendo nuove possibilità. L’Open Source è un richiamo alla comunità, un invito a partecipare e contribuire in modo significativo.”…
Server software
Flask è un micro-framework Python leggero e flessibile usato per costruire applicazioni web e API, fungendo da server software gestendo rotte HTTP, interazioni con database e rendering di template (Jinja2) per generare risposte dinamiche, con un server integrato per lo sviluppo e la possibilità di deployment su server reali (come Gunicorn/uWSGI) per la produzione, ideale per chi vuole controllo e semplicità, da semplici interfacce a sistemi complessi.
Come funziona come server:
- Micro-framework: Fornisce solo le basi essenziali, permettendo di aggiungere librerie esterne per funzionalità specifiche, rendendolo flessibile.
- Routing: Mappa gli URL (es. /login, /prodotti) a specifiche funzioni Python che gestiscono la logica per quelle richieste.
- Richieste/Risposte HTTP: Gestisce le richieste in entrata (GET, POST, ecc.) e restituisce risposte (HTML, JSON, ecc.).
- Server di sviluppo: Include un server WSGI (Werkzeug) integrato per testare l’app localmente con app.run().
- Rendering Template: Utilizza Jinja2 per creare pagine HTML dinamiche, inserendo dati Python direttamente nei file HTML.
- Estensibilità: Si integra con molte estensioni per aggiungere funzionalità come autenticazione (Flask-Login), database (SQLAlchemy) e altro.
Casi d’uso principali:
- Sviluppo web backend: Creare API RESTful o siti web completi.
- Strumenti di scripting: Interfacce web per script scientifici o di analisi dati.
- IoT: Piccoli server web embedded.
- Prototipazione rapida: Lanciare rapidamente un server per un progetto.
Da sviluppo a produzione:
- Durante lo sviluppo si usa il server integrato.
- Per il deployment, si usano server WSGI più robusti come Gunicorn o uWSGI, spesso dietro un proxy inverso come Nginx, per gestire il traffico reale.
Il software inerente un dispositivo che finge da Server, può essere concepito in due parti distinte:
La parte “Backend” (lato server) gestisce la logica di business, i database e l’infrastruttura nascosta all’utente (gestita da software come Python, Node.js, Java), mentre la parte “Frontend” (lato client) è l’interfaccia utente visibile e interattiva (gestita da software e linguaggi HTML, CSS, JavaScript, React, Vue) che comunica con il backend tramite API, entrambi essenziali per il funzionamento completo di un’applicazione web o mobile.
Il frontend si occupa di ciò che si vede e permette l’interazione, il backend di come le cose funzionano dietro le quinte.
Frontend (Lato Client):
- Cos’è: La parte dell’applicazione che l’utente vede e con cui interagisce direttamente (interfaccia utente).
- Cosa fa: Rendering di pagine, interattività, design responsivo, esperienza utente (UX).
- Tecnologie Comuni: HTML, CSS, JavaScript, e framework/librerie come React, Angular, Vue.js.
- Esempio: Un modulo di login (eventuale), i pulsanti, le icone, il layout del sito web.
Backend (Lato Server):
- Cos’è: La parte “dietro le quinte” che fa funzionare tutto, non visibile all’utente.
- Cosa fa: Gestisce dati (database), logica applicativa, sicurezza, autenticazione, comunicazione con altri servizi.
- Tecnologie Comuni: Linguaggi come Python (Django, Flask), Node.js (Express), Java (Spring), PHP, Ruby; Database come MySQL, PostgreSQL; Server come Apache, Nginx.
- Esempio: Salvare i dati di un monitoraggio, processare i dati e settare allarmi, gestire le icone, i pulsanti e inviare ad altri eventuali client dei comandi.
Come Collaborano:
- Il backend elabora (sempre in ascolto) elabora i dati ricevuti (eventualmente salva i dati in un database) e invia una risposta al frontend.
- Il frontend (sempre disponibile all’utente) espone i dati elaborati e attende eventuali comandi (es. “modifica setting allarmi”) al backend.
- Le API (Application Programming Interfaces) sono il ponte cruciale per questa comunicazione, permettendo a frontend e backend di “conversare”.
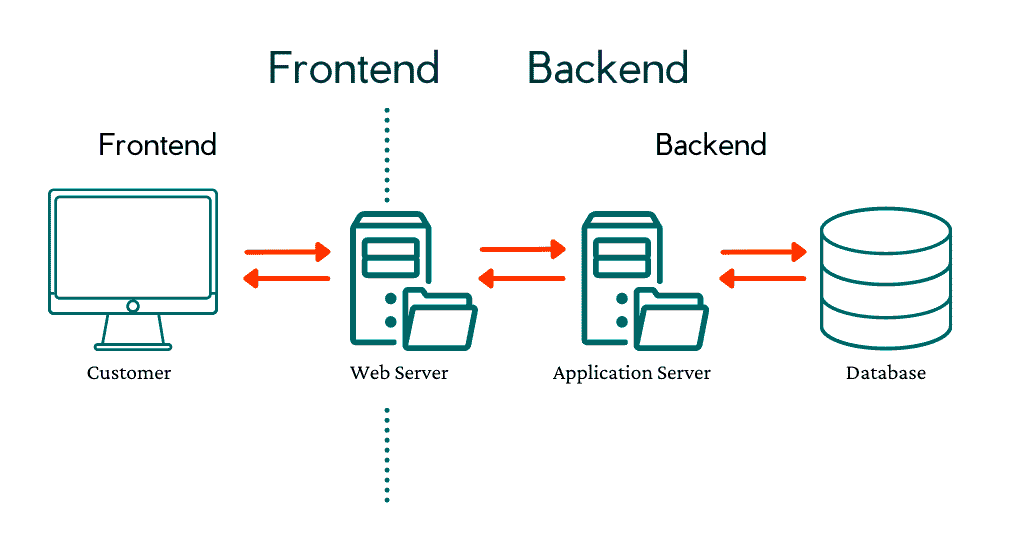
In questa applicazione minimale, ad uso didattico, si è cercato di ridurre all’essenziale la complessità software necessaria per la gestione della applicazione seguendo le linee di base inerenti l’architettura di Flask, organizzando nelle seguenti cartelle il software:
Il file Index.html
Il file index.html è file principale e di ingresso di un sito web, una pagina HTML che viene caricata automaticamente dal server quando un utente visita il dominio, per il framework Flask, questa pagina si trova in una specifica cartella denominata templates.
È scritto in HTML (HyperText Markup Language) per organizzare testi, immagini, link e altri elementi.
Il file viene letto dal browser (Chrome, Firefox, ecc.) e visualizzato come pagina web interattiva.
Il suo funzionamento può essere integrato con script di altri linguaggi, che ne condizionano l’aspetto (come i fogli di stile CSS) e l’interattività, come codice JS (JavaScript) per aggiungere funzionalità dinamiche, pulsanti interattivi e manipolazione dei dati.

Il listato di index.html
<html lang="it">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>IoT Dashboard - Raspberry Pi</title>
<!-- Refresh page every 30 seconds to fetch new data -->
<meta http-equiv="refresh" content="30">
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<!-- Google Fonts for premium look -->
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Outfit:wght@300;400;600&display=swap" rel="stylesheet">
</head>
<body>
<div class="container">
<header>
<h1>Monitoraggio Ambientale</h1>
<p>Ultimo aggiornamento: {{ data.last_updated if data.last_updated else 'In attesa di dati...' }}</p>
</header>
<main class="dashboard">
<!-- Temperature Card -->
<div class="card {% if alarms.temp_alarm %}alarm-{{ alarms.temp_alarm }}{% endif %}">
<div class="icon">??</div>
<h2>Temperatura</h2>
<div class="value">
{% if data.temperature is not none %}
{{ data.temperature }} C
{% else %}
--
{% endif %}
</div>
<div class="status">
{% if alarms.temp_alarm == 'min' %}
?? ALLARME: Temperatura Bassa (< 5 C)
{% elif alarms.temp_alarm == 'max' %}
?? ALLARME: Temperatura Alta (> 25 C)
{% else %}
Normale
{% endif %}
</div>
</div>
<!-- Humidity Card -->
<div class="card {% if alarms.hum_alarm %}alarm-{{ alarms.hum_alarm }}{% endif %}">
<div class="icon">?</div>
<h2>Umidity</h2>
<div class="value">
{% if data.humidity is not none %}
{{ data.humidity }} %
{% else %}
--
{% endif %}
</div>
<div class="status">
{% if alarms.hum_alarm == 'min' %}
?? ALLARME: Umidity Bassa (< 20%)
{% elif alarms.hum_alarm == 'max' %}
?? ALLARME: Umidity Alta (> 75%)
{% else %}
Normale
{% endif %}
</div>
</div>
</main>
<footer>
<p>Server: Raspberry Pi | Client: Pico W</p>
</footer>
</div>
</body>
</html>Note:
Si noti che vengono richiamate due “card”, fornite dalla App.py per esporre i dati sulla pagina index.html, il cui stile viene architettato tramite un file di stile: syles.css.
Il file syles.css
I fogli di stile CSS (Cascading Style Sheets) sono una raccolta di regole di formattazione che controllano l’aspetto del contenuto di una pagina Web.
Questa tipologia architetturale viene utilizzata per formattare una pagina, il contenuto viene dunque separato dalla presentazione.
Il codice HTML, si trova dunque nel file HTML, mentre le regole CSS che definiscono la presentazione del codice si trovano in un altro file (un foglio di stile esterno e, nel caso d’uso di flask, nella cartella static) ma in altri casi può coesistere nel listato HTML (in genere nella sezione head).
Separando il contenuto dalla presentazione, è molto più facile gestire l’aspetto del sito da un unico punto di controllo, poiché non è necessario aggiornare ogni proprietà di ogni pagina quando si vuole effettuare una modifica, inoltre, si ottiene un codice HTML più semplice e “pulito”, che abbrevia i tempi di caricamento nel browser e semplifica la navigazione.
I CSS offrono più flessibilità e più controllo sui dettagli dell’aspetto delle pagine.
Con i CSS si possono controllare molte proprietà del testo:
- caratteri e dimensioni di carattere particolari;
- elementi di formattazione come grassetto, corsivo, sottolineatura e ombreggiatura del testo;
- colore del testo e colore di sfondo;
- colore e sottolineatura dei collegamenti; ecc.
Utilizzando i CSS per controllare i caratteri, si possono inoltre gestire layout e aspetto della pagina in modo più omogeneo indipendentemente dal browser utilizzato.
Oltre alla formattazione del testo, si possono utilizzare i CSS per controllare il formato e la posizione di elementi a livello di blocco in una pagina Web.
Un elemento a livello di blocco è una parte di contenuto autonoma, solitamente separata da un carattere di nuova riga nel codice HTML e formattato visivamente come un blocco. In questo caso le “card” fornite dalla App. Flask.
Si possono impostare margini e bordi per gli elementi a livello di blocco, collocarli in una posizione specifica, aggiungervi un colore di sfondo, fare scorrere il testo attorno ad essi e così via.
La manipolazione degli elementi a livello di blocco è essenzialmente il metodo con cui si organizza il layout delle pagine quando si usano i CSS.
Il listato di styles.css
:root {
--bg-color: #0f172a; /* Dark blue/slate background */
--card-bg: #1e293b;
--text-primary: #f8fafc;
--text-secondary: #94a3b8;
--accent-color: #38bdf8; /* Cyan */
--alarm-min: #0ea5e9; /* Blue for cold/low */
--alarm-max: #ef4444; /* Red for hot/high */
--alarm-bg-min: rgba(14, 165, 233, 0.2);
--alarm-bg-max: rgba(239, 68, 68, 0.2);
--success-color: #22c55e;
}
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
body {
font-family: 'Outfit', sans-serif;
background-color: var(--bg-color);
color: var(--text-primary);
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
}
.container {
width: 100%;
max-width: 800px;
padding: 2rem;
text-align: center;
}
header h1 {
font-weight: 600;
font-size: 2.5rem;
margin-bottom: 0.5rem;
background: linear-gradient(to right, var(--accent-color), #818cf8);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
}
header p {
color: var(--text-secondary);
margin-bottom: 3rem;
font-size: 1.1rem;
}
.dashboard {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(300px, 1fr));
gap: 2rem;
}
.card {
background-color: var(--card-bg);
border-radius: 1.5rem;
padding: 2rem;
box-shadow: 0 10px 15px -3px rgba(0, 0, 0, 0.1), 0 4px 6px -2px rgba(0, 0, 0, 0.05);
transition: transform 0.3s ease, box-shadow 0.3s ease;
border: 1px solid rgba(255, 255, 255, 0.1);
}
.card:hover {
transform: translateY(-5px);
box-shadow: 0 20px 25px -5px rgba(0, 0, 0, 0.2);
}
.icon {
font-size: 3rem;
margin-bottom: 1rem;
}
.card h2 {
font-weight: 400;
color: var(--text-secondary);
font-size: 1.2rem;
text-transform: uppercase;
letter-spacing: 0.1em;
margin-bottom: 1rem;
}
.value {
font-size: 4rem;
font-weight: 600;
margin-bottom: 1rem;
}
.status {
padding: 0.5rem 1rem;
border-radius: 9999px;
background-color: rgba(255, 255, 255, 0.05);
display: inline-block;
font-size: 0.9rem;
}
/* Alarm States */
.card.alarm-min {
border-color: var(--alarm-min);
background-color: var(--alarm-bg-min);
}
.card.alarm-min .value {
color: var(--alarm-min);
}
.card.alarm-max {
border-color: var(--alarm-max);
background-color: var(--alarm-bg-max);
}
.card.alarm-max .value {
color: var(--alarm-max);
}
footer {
margin-top: 4rem;
color: var(--text-secondary);
font-size: 0.8rem;
}
@media (max-width: 600px) {
header h1 {
font-size: 2rem;
}
.value {
font-size: 3rem;
}
}CSS In sintesi:
- Linguaggio di formattazione: I CSS definiscono il modo in cui i documenti HTML/XML vengono presentati.
- Separazione: Separano contenuto (HTML) dalla presentazione (CSS), rendendo i siti più gestibili e accessibili.
- “A cascata”: Le regole vengono applicate in un ordine specifico, permettendo a stili più specifici di sovrascrivere quelli più generali.
Come funzionano (sintassi di base)
- Un foglio CSS è composto da regole.
- Ogni regola ha un selettore (es.
p,#mioId,.miaClasse) e un blocco di dichiarazioni{},. - Le dichiarazioni sono coppie proprietà: valore; (es.
color: blue;
La App di Flask
I punti fondamentali per l’utilizzo di una applicazione in flask possono essere identificati come di seguito esposto:
- Installazione: Si installa tramite pip (
pip install flask). - Creazione dell’istanza: Si crea un oggetto
Flask(__name__). - Routing: Si definiscono le rotte (URL) che mappano funzioni Python (es.
@app.route('/')). - Gestione richieste: Si usano oggetti come
requestper gestire dati da form (POST). - Rendering: Si usa
render_template()per generare pagine HTML dinamicamente da template (file .html nella cartellatemplates). - Sessioni e Sicurezza: Si gestiscono le sessioni utente tramite cookie e si configura una chiave segreta (
SECRET_KEY) per la sicurezza, preferibilmente con estensioni come Flask-Login per applicazioni reali.
Il linguaggio utilizzato è Python!
La storia di Python inizia nel 1989, quando il programmatore olandese Guido van Rossum iniziò a lavorarci durante le vacanze di Natale, rilasciando la prima versione nel 1991; il nome deriva dal gruppo comico britannico Monty Python, non dai serpenti, riflettendo l’intento di creare un linguaggio semplice, leggibile e divertente.
Python si è evoluto da un progetto personale a un linguaggio di programmazione di alto livello, ampiamente usato grazie alla sua sintassi chiara, flessibilità e vasta libreria, diventando uno dei più popolari per lo sviluppo web, l’analisi dati e l’IA.
Nascita e prime versioni:
- 1989: Guido van Rossum inizia lo sviluppo di Python, ispirato dal linguaggio ABC e cercando un linguaggio di scripting per le vacanze.
- 1994: Esce Python 1.0, introducendo funzionalità come map, filter e reduce
Sviluppo e diffusione:
- 2000: Viene rilasciato Python 2.0, con supporto Unicode e miglioramenti nelle liste.
- 2008: Esce Python 3.0, introducendo cambiamenti significativi come la funzione
print()e miglioramenti nella gestione numerica. - Filosofia: Guido van Rossum, in qualità di “Benevolent Dictator For Life” (BDFL), ha guidato lo sviluppo, enfatizzando la leggibilità del codice (simile all’inglese) e la facilità d’uso.
- Popolarità: La sua semplicità lo rende ideale per i principianti, mentre la potenza e le librerie lo rendono adatto a professionisti per sviluppo web (Django, Flask), data science, machine learning e scripting.
Python è un linguaggio di programmazione open source, gratuito, liberamente utilizzabile, modificabile e distribuibile anche per scopi commerciali, supportato da una licenza approvata dalla Python Software Foundation (PSF), il che lo rende flessibile, versatile e privo di costi di licenza per aziende e sviluppatori.
Il listato di app.py
# versione B_01 correzione errori utf8
# funziona su raspberyy pi 4b
from flask import Flask, render_template, request, jsonify
from datetime import datetime
app = Flask(__name__)
# Global variables to store the latest sensor data
# Initialize with None to indicate no data received yet
latest_data = {
'temperature': None,
'humidity': None,
'last_updated': None
}
# Alarm thresholds
TEMP_MIN = 5.0
TEMP_MAX = 25.0
HUM_MIN = 20.0
HUM_MAX = 75.0
@app.route('/')
def index():
"""Render the dashboard with current data and alarm status."""
data = latest_data.copy()
alarms = {
'temp_alarm': None,
'hum_alarm': None
}
if data['temperature'] is not None:
if data['temperature'] < TEMP_MIN:
alarms['temp_alarm'] = 'min' # Low temperature alarm
elif data['temperature'] > TEMP_MAX:
alarms['temp_alarm'] = 'max' # High temperature alarm
if data['humidity'] is not None:
if data['humidity'] < HUM_MIN:
alarms['hum_alarm'] = 'min' # Low humidity alarm
elif data['humidity'] > HUM_MAX:
alarms['hum_alarm'] = 'max' # High humidity alarm
return render_template('index.html', data=data, alarms=alarms)
@app.route('/upload', methods=['POST'])
def upload_data():
"""Receive sensor data from the client."""
try:
content = request.json
temp = content.get('temperature')
hum = content.get('humidity')
if temp is not None and hum is not None:
latest_data['temperature'] = float(temp)
latest_data['humidity'] = float(hum)
latest_data['last_updated'] = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Received data: Temp={temp} C, Humidity={hum}%")
return jsonify({"status": "success", "message": "Data received"}), 200
else:
return jsonify({"status": "error", "message": "Invalid data format"}), 400
except Exception as e:
print(f"Error processing upload: {e}")
return jsonify({"status": "error", "message": str(e)}), 500
if __name__ == '__main__':
# Run server on all interfaces, port 5000
app.run(host='0.0.0.0', port=5000, debug=True)
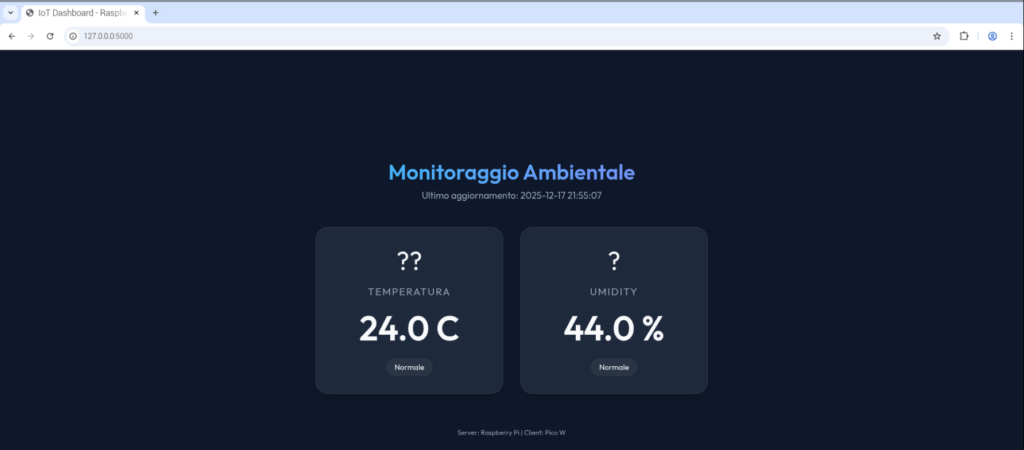
E finalmente eccolo! L’host che attraversa la porta del locale, per servire in un piatto d’argento gli estratti della spremitura dei sensori, su dei calici cristallini di HTML.
Consigli di lettura:

Grazie per la vostra attenzione.
Romeo Ceccato